


Pourquoi les entreprises devraient s’intéresser aux lacs de données?
Selon Gartner, les entreprises n’utilisent pas plus d’un pour cent de leurs données à des fins de prise de décision et d’analyse. Ce n’est pas parce qu’elles choisissent d’ignorer les autres 99% de leurs données. C’est plutôt parce que la plupart des entreprises ne savent pas comment accéder et traiter leurs propres données pour en extraire le plein potentiel. Comme mentionné dans notre article sur l’IA omnicanal, 54% des répondants à une enquête Emarketer ont déclaré que leur principal obstacle est l’incapacité d’analyser et de donner un sens à leurs données. Par conséquence, les entreprises prennent de nombreuses décisions basées sur une image très incomplète de la réalité.
La création d’un lac de données est une excellente première étape pour découvrir de nouvelles opportunités ainsi que des menaces imprévues. Si votre organisation ne dispose pas encore d’un lac de données, le moment n’aura jamais été aussi propice pour envisager d’en créer un. Les données deviennent l’un des atouts stratégiques les plus importants qu’une entreprise puisse utiliser pour générer de la croissance et tenter de prédire l’avenir, en particulier en cette période très imprévisible de l’après-COVID-19. En fait, une mauvaise exploitation analytique pourrait laisser traîner des millions de dollars sous vos données.
Basé à la fois sur l’expérience professionnelle des clients et sur une recherche universitaire approfondie, cet article de fond vous permettra de mieux comprendre ce qu’est un lac de données et comment il peut être mis en œuvre par votre organisation. Notre but est avant tout d’offrir à la communauté professionnelle de l’analytique et des TI une base conceptuelle solide et des conseils pratiques pour vous aider à démarrer votre projet de lac de données.
De l'entreposage des données aux lacs de données
Au début des années 2000, avec l’augmentation des exigences en matière de collecte de données, les bases de données relationnelles ne pouvaient plus à elles seules faire face à la taille et à la diversité des données stockées par de nombreuses entreprises et organisations. Par conséquent, la mise en place d’entrepôts de données et de modèles d’analyse dimensionnelle, notamment le traitement analytique en ligne (OLAP), est apparue comme un cadre plus adapté aux équipes d’intelligence d’affaires.
Les besoins de modélisation multidimensionnelle de l’entreposage de données ont à leur tour produit des théories fonctionnelles provenant de pionniers comme Ralph Kimball et Bill Inmon, qui ont fourni des solutions pour exploiter ces nouveaux systèmes à partir de sources de données multiples.
Cette situation a grandement évolué au cours des 10 à 20 dernières années, lorsque des entreprises comme Google, Facebook, YouTube et Amazon ont vu la taille et la diversité structurelle de leurs données croître de manière exponentielle, ce qui a nécessité des changements radicaux dans la gestion des données. Ce besoin a donné naissance à des cadres de travail comme Hadoop, ainsi qu’à MapReduce (qui remonte au document de recherche de Google publié en 2004) et finalement à Apache Spark, permettant de fournir de meilleures solutions pour les grandes infrastructures de données. Comme les données massives ont poursuivi leur croissance et que les problèmes de gestion des données se sont étendus à un plus grand nombre d’entreprises et d’organisations, cela a donné lieu à une nouvelle phase dans l’évolution des systèmes de stockage de fichiers, sous la forme de lacs de données. Ces écosystèmes pouvaient accueillir non seulement des données structurées, mais aussi des structures de données polymorphes, connues également sous le nom de données semi-structurées et non structurées.
Qu’est-ce qu’un lac de données?
Tel que nous le démontrerons plus loin dans l’article, les principaux cas d’utilisation et les défis de mise en œuvre entourant la création d’un lac de données sont de mieux en mieux documentés. Cependant, la confusion persiste quant à la topologie du lac de données lui-même. Tout d’abord, existe-t-il une définition claire de ce qu’est un lac de données ? Contrairement aux entrepôts de données, dont la définition structurelle est bien établie par les travaux (et le débat) de Kimball et Inmon, il est plus difficile de parvenir à un consensus sur la définition fonctionnelle d’un lac de données. Pour l’essentiel, le concept a émergé de façon organique en fonction des besoins de l’industrie.
L’interprétation la plus courante est probablement celle de James Dixon, fondateur et ancien directeur technique de Pentaho. Dixon est celui qui a inventé en 2010 le terme « Data Lake » et dont la définition est parmi les plus citées dans l’industrie. Selon Dixon, un lac de données peut être décrit comme suit par rapport à un magasin de données :
« Comparons un magasin de données à un magasin d’eau en bouteille. L’eau qui s’y trouve est traitée, conditionnée et structurée pour être consommée plus facilement. Le contenu du lac de données, s’apparente quant à lui, à un lac depuis lequel divers usagers peuvent faire des observations, y plonger ou y prélever des échantillons. »
Une autre définition un peu plus structurée a été proposée lors d’un débat entre Tamara Dull et Anne Buff, disponible sur le site d’analyse populaire Kdnuggets.com. La définition utilisée au cours du débat était la suivante :
« Un lac de données est un dépôt de stockage qui contient une vaste quantité de données brutes dans leur format d’origine, y compris des données structurées, semi-structurées et non structurées. La structure des données et les exigences ne sont pas définies tant que les données ne sont pas requises. »
Dans la littérature scientifique, Snezhana Sulova, de l’Université de sciences économiques de Varna (faculté des sciences informatiques), a présenté une interprétation du lac de données dans un article qui le décrit davantage comme une stratégie de stockage des données. Un autre couple de chercheurs en doctorat, Cédrine Madera et Anne Laurent, ont également contribué à une définition technique élaborée du lac de données comme une nouvelle étape dans l’évolution de l’architecture de l’information pour les systèmes d’aide à la décision. L’article de Cédrine Madera et Anne Laurent passe méticuleusement en revue un grand nombre de propriétés fondamentales associées aux lacs de données. Cependant, comme leur définition a été écrite dans les premières années des cadres Hadoop et MapReduce, la méthode principale de traitement des données qu’ils associent aux lacs de données est strictement limitée aux techniques de chargement par lots. Aujourd’hui, cette méthode est manifestement erronée, car elle ne tient pas compte des avancées plus récentes en matière de streaming en temps réel, comme avec Apache Spark, Kafka, Google’s Pub/Sub ou Apache Beam. Ces derniers sont devenus une composante fondamentale de l’évolution des lacs de données au cours des dernières années. Le streaming en temps réel a contribué à l’explosion de la taille de la collecte de données, notamment en simplifiant l’intégration des données des capteurs des appareils IoT (Internet of Things).
Le concept de gravité des données (data gravity)
Une autre caractéristique distinctive des lacs de données concerne une nouvelle théorie appelée data gravity. L’idée a été développée par Dave McCrory en 2010 qui a depuis fait son chemin dans la littérature professionnelle et universitaire, et est devenue le sujet de discussions et de débats dans diverses conférences sur les TI. McCrory a mis au point une formule mathématique pour appuyer sa théorie. En résumé, la gravité des données démontre que les données ont une masse et, par extension, une force d’attraction gravitationnelle qui leur est propre. Selon McCrory, « cette attraction (force gravitationnelle) est causée par la nécessité pour les services et les applications d’avoir un accès aux données à plus grande largeur de bande et/ou à plus faible latence ». Dans un lac de données, le concept de gravité des données est souvent discuté en tenant compte des difficultés de déplacement des données après qu’elles aient atteint une certaine « masse critique ».
Le rôle des lacs dans l'écosystème analytique
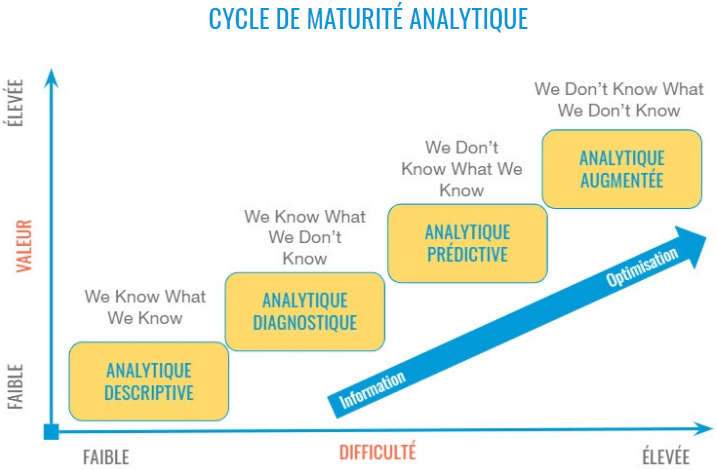
Toutes ces explications sont utiles pour mieux cerner le rôle du lac de données dans les environnements d’intelligence d’affaires et de marketing. L’idée serait de créer une banque de données centralisée sans les règles rigides et parfois restrictives des entrepôts de données. Sur la base de cette définition, il pourrait être intéressant de classer le rôle du lac de données selon la carte des connaissances de Stephen Drew :
-png-2.png)
Sur la base de ce modèle, le lac de données peut couvrir tous les quadrants de la carte des connaissances d’une organisation, même le plus complexe, le cadran n°4 : « Ce que nous ne savons pas, nous ne le savons pas ». En effet, c’est ce que les données massives à l’état brut ont le potentiel de mettre en évidence au sein d’une entreprise. C’est pourquoi ces lacs sont très souvent exploités à titre exploratoire par des spécialistes des données, dont l’objectif est la découverte de nouveaux modèles de données, qui peuvent donner lieu à de nouvelles solutions commerciales ou marketing, et surtout, identifier de nouvelles questions, ce qui apporte une valeur stratégique pour une équipe de veille commerciale ou marketing.
Pour une entreprise, le choix entre un lac de données et un entrepôt de données dépend de nombreux facteurs, notamment la vitesse à laquelle votre organisation peut atteindre sa maturité analytique. Pour en savoir plus sur la différence entre les lacs de données et les entrepôts de données, vous pouvez lire notre article sur le sujet : La différence entre les lacs de données et les entrepôts de données.
La première étape pour une organisation consiste généralement à maîtriser les données analytiques descriptives et diagnostiques, qui peuvent fournir un portrait clair des performances. La meilleure façon de répondre à ces besoins est de mettre en place un entrepôt de données solide. Au fur et à mesure que la pratique de l’analyse se développe, l’entreprise peut progressivement passer à l’analyse prédictive et, en fin de compte, se préparer à l’analyse augmentée (c’est-à-dire le traitement du langage naturel et l‘intelligence artificielle). Chaque étape de la maturité apporte une valeur ajoutée à l’entreprise. Toutefois, chaque étape s’accompagne de niveaux de complexité et d’expertise technique croissants. Il peut donc être judicieux commencer par ramper ou du moins d’essayer de marcher avant de courir vers un écosystème analytique plus avancé.
Quoi faire et ne pas faire avec un lac de données?
Si vous envisagez la création d’un lac de données pour votre organisation, voici une liste des bonnes pratiques (et moins bonnes) à garder à l’esprit lors de la planification de votre projet :
À faire
- Décrivez les principales les principaux objectifs que vous souhaitez atteindre t les questions que vous souhaitez répondre avec un lac de données. Notez également les les choses que vous ne pouvez pas réaliser actuellement avec votre entrepôt de données ou vos bases de données existantes ;
- Avant d’aller plus loin, définissez les cas d’utilisation analytiques que vous souhaitez remplir et évaluez la valeur commerciale et leur impact potentiel ;
- Évaluez l’éventail des sources de données que vous devrez intégrer dans un environnement de lac de données et établissez un catalogue préliminaire de métadonnées.
À éviter
- N’essayez pas de mettre en œuvre votre lac de données sans d’abord tester une preuve de concept, comme la construction d’un « mini lac », qui peut être utilisé pour un projet à but unique ou pour répondre à un seul cas d’utilisation ;
- Faites attention aux promesses des vendeurs de technologies et des fournisseurs de cloud qui vous promettent un lac de données en quelques clics seulement ;
- Ne confiez pas le projet de lac de données exclusivement au département des TI, au marketing ou à une équipe spécifique. Un projet de lac de données doit être un effort transversal et surtout un effort d’équipe!
Maintenant que nous avons une compréhension plus claire de ce qu’est un lac de données et de son rôle dans l’écosystème analytique, la prochaine étape consiste à comprendre quels sont les principaux cas d’utilisation et les défis liés à sa mise en œuvre.
Cas d'utilisation de base et défis
En 2018, la professeure de l’université d’Agder (UiA) Marilex Rea Llave publie un article dans lequel elle présente son point de vue sur l’utilisation des lacs de données par les praticiens de l’intelligence d’affaires. Elle y regroupe notamment l’analyse des interactions entre les membres d’un groupe de discussion composé de 12 experts norvégiens en intelligence d’affaires. Ces experts provenaient de divers secteurs d’activité pour essayer de comprendre la contribution des lacs de données dans différents environnements et réalités d’affaires. L’article donne des perspectives intéressantes sur la question suivante : Quels sont les principaux cas d’utilisation et les principaux défis de mise en œuvre des lacs de données ?
D’après les entretiens menés par Llave, il existe trois principaux cas d’utilisation du lac de données:
- Ils peut être utilisé comme zone de transit ou source de données pour les entrepôts de données;
- Ils peut être utilisé comme plate-forme expérimentale pour les scientifiques ou les analystes de données;
- Ils peut être utilisé comme source de donnée directe pour le BI en libre-service. pour accéder à des données atypiques.
Son analyse a également identifié cinq grands défis liés à la mise en œuvre de ces lacs, notamment
- Gérance des données. Qui est responsable du lac et qui l’entretient au sein de l’organisation ?
- La gouvernance des données. Comment pouvons-nous assurer la gouvernance d’une collecte de données à la fois massive disparate ?
- Le besoin en ressource humaine. Quel type de profil d’embauche doit être envisagé pour gérer l’infrastructure d’un lac ?
- La qualité des données. Comment gérer la qualité des données qui entrent dans les lacs étant donné leur manque d’organisation par rapport aux entrepôts ?
- Récupération des données. Comment extraire les données d’un lac pour en extraire une valeur analytique ? (par exemple, les données des capteurs IdO)
Tous ces défis sont importants à prendre en compte lors de la conception de la mise en œuvre d’un lac de données au sein d’une organisation. D’autres auteurs disposent de listes similaires à celle de Llave, notamment dans un article publié par Miloslavskaya et Tolstoï, dans lequel les auteurs décrivent douze facteurs clés à prendre en compte lors d’une mise en œuvre. Si vous souhaitez en savoir plus sur ces douze facteurs, vous pouvez consulter leur article dans les références ci-dessous, à la fin de cet article.
Un cadre pour la conception des lacs de données
Bien que les facteurs et défis clés aient été bien décrits par les universitaires cités ci-dessus, nous n’avons toujours pas de cadre de travail standardisé pour pour permettre aux entreprises de les relever. Contrairement aux entrepôts de données, il n’existe toujours pas de plan précis pour la conception des lacs de données. Le meilleur effort à ce jour se trouve probablement dans un livre écrit en 2019 par Alex Gorelik intitulé « The Enterprise Big Data Lake : Delivering the Promise of Big Data and Data Science« . Ce livre fournit une base solide sur laquelle les ingénieurs informatiques et les ingénieurs de données peuvent s’appuyer pour travailler. Toutefois, il ne s’agit pas exactement d’un cadre au sens strict du terme.
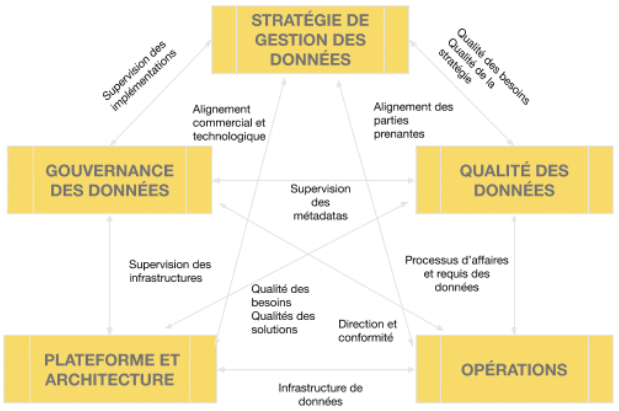
Pour une démarche plus complète, un compagnon très approprié au livre de Gorelix sont les six thèmes clés du modèle de maturité de la gestion des données (DMM) du CMMI. Ce cadre fournit une méthodologie testée par Fortune 500 (et même par la NASA) à partir de laquelle les équipes informatiques et de gestion des données peuvent travailler lorsqu’elles planifient un projet à grande échelle comme un lac de données. Voici à quoi ressemble la relation entre les six thèmes de gestion des données du modèle DMM :
L'architecture des lacs de données: infonuagique ou physique (on-premise)?
Une fois les objectifs d’affaires, les cas d’utilisation identifiés, ainsi que le cadre de gestion informatique (c’est-à-dire le DMM), le moment est venu de réfléchir au type d’architecture qui sera déployé pour le lac. Cette partie est très importante et critique pour le succès du projet.
Parmi les décisions clés à prendre, il y a la question de passer au « cloud » sans serveur ou de tout garder sur place dans les grands centres de données. Généralement, les organisations qui ont des considérations de sécurité élevées préféreront le site sur place, tandis que les entreprises plus agiles et plus souples préféreront le nuage. Une troisième option est de passer à l’hybride et de mélanger les deux, afin d’obtenir le meilleur des deux mondes.
Les services en infonuagique sont très populaires de nos jours et ont tendance à convenir à de nombreux cas d’utilisation et à de nombreuses charges de travail. C’est probablement la raison pour laquelle Deloitte rapporte qu’un tiers (34 %) des entreprises affirment avoir déjà entièrement mis en œuvre la modernisation des données dans le nuage. Par ailleurs, 50 % des entreprises déclarent être en train de moderniser leur gestion de données.
La question est de savoir comment vous pouvez faire le bon choix lorsque vous modernisez votre infrastructure ou que vous déployez de nouveaux services de données. Et comment pouvez-vous vous assurer que vos données sont sécurisées ? Ce qu’il faut retenir, c’est que chaque voie a ses propres avantages et inconvénients. Il n’y a pas de solution miracle. De plus, il est trompeur de croire que le passage à l’infonuagique signifie choisir une option simple. Le cloud peut certainement être plus simple que la mise en œuvre sur site physique, mais cela ne signifie pas qu’il est simple en soi. En fait, 47 % des professionnels du cloud computing pensent que la complexité est le principal risque pour le retour sur investissement (Deloitte 2019) Par conséquent, une analyse fonctionnelle de vos principaux cas d’utilisation, réalisée soit par votre propre équipe TI, soit par un consultant externe, vous évitera bien des maux de tête à l’avenir. Les architectures des lacs de données peuvent être très difficiles à maintenir et un risque majeur est de transformer votre lac en un marécage de données.
De plus, si vous choisissez d’utiliser une option cloud, comme le feront la plupart des entreprises, il est important d’évaluer la nature et l’importance des sources de données les plus importantes de l’entreprise. En effet, certains fournisseurs de cloud peuvent être plus adaptés à certains types de données. Par exemple, si votre entreprise est profondément investie dans un écosystème Microsoft, Azure peut ou non être une meilleure option pour vous. D’un autre côté, si votre entreprise a une forte empreinte marketing numérique, avec beaucoup de données provenant de Google Analytics, Google Cloud pourrait peut-être mieux convenir.
Une autre question est de savoir combien de vos sources de données ont déjà des connexions API préexistantes exploitables ? Combien de sources auront besoin d’une solution API personnalisée ? Lequel des fournisseurs de cloud computing que vous envisagez à un partenaire qui intègre la plupart des sources de données ou des plateformes utilisées par votre entreprise ? Toutes ces questions peuvent trouver une réponse grâce à une analyse fonctionnelle bien planifiée de vos cas d’utilisation et de vos besoins d’affaires. En fin de compte, la façon dont vous traiterez ces questions vous permettra de déterminer « Comment pouvons-nous stocker les données » ou, « Que pouvons-nous faire avec toutes les données ?
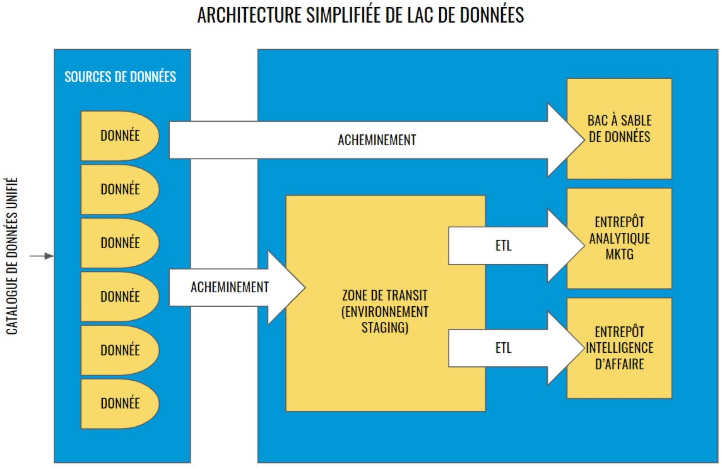
En termes d’architecture, les plans varient énormément d’une organisation à l’autre. Cependant, une version simplifiée de l’architecture d’un lac de données devrait comprendre les éléments suivants :
- Un catalogue de données unifié comprenant toutes les sources ;
- Une zone de transit où les données seront ingérées pour être traitées avant de passer à un travail ETL ou à d’autres transformations ;
- Un bac à sable pour la science des données pour l’exploration brute qui contournera généralement la zone de transit ;
- Un ou plusieurs entrepôts de données dédiés aux emplois ETL pour les rapports d’intelligence d’affaire et/ou d’analyse marketing.
Nous espérons que cet article vous a été utile et vous a permis de mieux comprendre ce qu’est un lac de données et ce qu’il peut offrir à votre organisation. Si vous souhaitez en savoir plus sur le sujet ou si vous avez besoin d’aide pour démarrer votre projet, n’hésitez pas à contacter notre équipe d’analyse et de science des données. En attendant, vous pouvez aller encore plus loin dans vos recherches en consultant toutes les références bibliographiques qui se trouvent ci-dessous.
Références
- ‘A Brief History of Data Lakes – DATAVERSITY’, available at https://www.dataversity.net/brief-history-data-lakes/, last accessed on Feb. 24, 2020.
- ‘Charting the data lake: Using the data models with schema-on-read and schema-on-write’, available at https://www.ibmbigdatahub.com/blog/charting-data-lake-using-data-models-schema-read-and-schema-write, last accessed on Feb. 24, 2020.
- ‘Data Gravity – in the Clouds, available at https://datagravitas.com/2010/12/07/data-gravity-in-the-clouds/, last accessed on Feb. 28, 2020.
- ‘Data Lake vs Data Warehouse: Key differences’, available at https://www.kdnuggets.com/2015/09/data-lake-vs-data-warehouse-key-differences.html, last accessed on Feb. 28, 2020.
- ‘Data Warehouse Design – Inmon versus Kimball – TDAN.com’ available at https://tdan.com/data-warehouse-design-inmon-versus-kimball/20300, last accessed on Feb. 27, 2020.
- Ahmed E., Yaqoob I., Abaker Targio Hashem I., Khan I., Abdalla Ahmed A.I., Imran M., Vasilakos A.V., 2017, ‘The role of big data analytics in Internet of Things’, Computer Networks, Volume 129, Part 2, p. 459-471.
- Dean J., Ghemawat S., 2004, ‘MapReduce: Simplified Data Processing on Large Clusters’, OSDI’04: Sixth Symposium on Operating System Design and Implementation, p. 137–150.
- Drew S., 1999, ‘Building Knowledge Management into Strategy: Making Sense of a New Perspective’, Long Range Planning, 32 (1), p.130-136.
- Khine P.P., Wang Z.S., 2018 [cited 2020 Feb. 19], ‘Data lake: a new ideology in big data era’, ITM Web Conf [Internet], ;17,03025.
- Kimball R. The data warehouse toolkit: practical techniques for building dimensional data warehouses. USA: John Wiley & Sons, Inc.; 1996.
- Llave M.R., 2018, ‘Data lakes in business intelligence: reporting from the trenches’, Procedia Computer Science, Volume 138, p. 516-524.
- Madera C., Laurent A., 2019, ‘The Next Information Architecture Evolution: The Data Lake Wave’, MEDES: Management of Digital EcoSystems, HAL Id: lirmm-01399005.
- Miloslavskaya N., Tolstoy A., 2016, ‘Big Data, Fast Data and Data Lake Concepts’, Procedia Computer Science, Volume 88, p. 300-305.
- Shvachko K. Kuang H., Radia S., Chansler R., 2010, ‘The Hadoop Distributed File System’, IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), p. 1–10.
- Sulova S., 2019, ‘The Usage of Data Lake for Business Intelligence Data Analysis’, Conferences of the Department Informatics, Publishing house Science and Economics Varna, Issue 1, p. 135-144.
- Walker C., Alrehamy H., 2015, ‘Personal Data Lake with Data Gravity Pull’. IEEE Fifth International Conference on Big Data and Cloud Computing, p. 160–167.
- Yessad L, Labiod A. Comparative study of data warehouses modeling approaches: Inmon, Kimball and Data Vault. In: 2016 International Conference on System Reliability and Science (ICSRS). 2016. p. 95–9.