


Data lakes are distinguished from data warehouses by the way in which data is stored without the need to transform it. Data lakes store data in its raw form whereas warehouses require rigid filtering before it can be collected. Additionally, data lakes are capable of easily collecting and storing data of any type.
The grid below outlines some of the main differences between data lakes and data warehouses. This article will further explain some important characteristics that make data lakes capable of handling very large volumes of data with high speed and variety. However, due to the size and lack of organization of data lakes, managing data veracity can be more difficult than with traditional data warehouses.
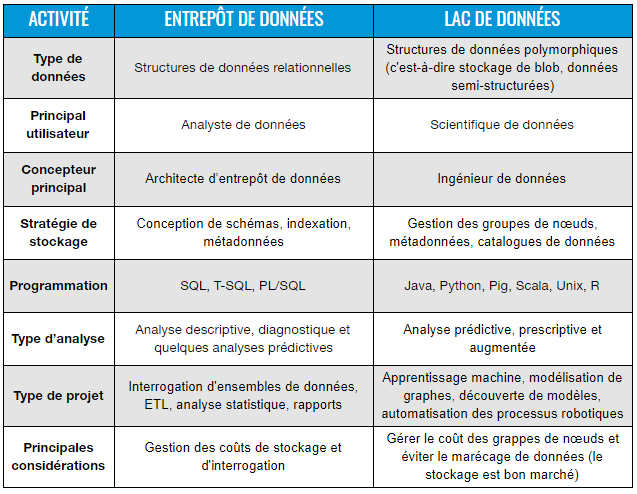
Comparative grid between data lakes and data warehouses
Besides the above grid elements, there is another fundamental difference between a data lake and a data warehouse, which is called schema management . While the warehouse operates according to a schema-on-write model via technical approaches like the standard ETL (Extract, Transform, Load), the lake operates according to a schema-on-read model named as part of Hadoop work. This is a subtle, but important distinction, since it gives data scientists the ability to explore raw data patterns with a data lake architecture.
In a data warehouse, if the data stored in a database does not match the format of the schema built for a particular table, the data is simply discarded. For example, in SQL, it is not possible to add data to the table without first creating it. Consequently, the creation of the table is only possible if the latter's schema has been predefined before the actual loading of the dataset. As a result, if the data is changed by adding fields or changing the data type, the table will need to be dropped or reloaded in order to fit in the database.
This classic schema-on-write approach is manageable for relatively small data sets or when it doesn't involve foreign keys affecting a large number of arrays. However, when dealing with foreign keys and multi-terabyte datasets, dropping or reloading tables can take days instead of minutes, while incurring significant computational costs. Fortunately, modern cloud-based solutions like BigQuery and Amazon Redshift have dramatically improved the computing power of data warehousing. However, for use cases requiring ACID (atomicity, consistency, isolation, durability) transactions with a response time of milliseconds, even BigQuery's powerful query engine is not enough. Furthermore,
With the "schema-on-read" approach, there are no prerequisites for loading files of any kind into a data lake. In fact, in the framework of Hadoop, which today is mainly managed in serverless cloud object stores like Google Cloud Storage, S3, etc., the process starts with loading a dataset without any modification . The line of code below is an example of a Hadoop Distributed File System (HDFS) command to load data into the equivalent of a standard table in a Hadoop environment:
hdfs dfs-copyFromLocal /temp/mktgfile*.txt
/user/hadoop/analytics
The command line above is an instruction in Python to extract all text files that start with mktgfile in the temp folder in the HDFS system. This command will initiate a whole background mapping and distribution process to optimize storage according to the Hadoop framework. From there, no schema is needed to go ahead and directly query that data from the table. In Python, this is what this query might look like:
hadoop jar Hadoop-streaming.jar
-mapper analytics-mapper.py
-reducer analytics-reducer.py
-input /user/hadoop/analytics/*.txt
-output /user/hadoop/output/query1
To manage Hadoop on a larger scale, YARN (Yet Another Resource Negotiator) was created as a cluster resource management layer, which is used for resource allocation and task scheduling. YARN was introduced in Hadoop version 2.0 and serves as a middle layer between HDFS and a processing framework called MapReduce , which we'll describe in a moment.
What is important to remember is that in this NoSQL universe, the data structure is only interpreted once it is read, which is at the heart of the idea of schema-on- read . Therefore, if a particular analysis file does not respect the structure of a predefined schema, such as if a field is added or deleted in a table, the mapping function in the above query will adjust to the stolen. Indeed, the data schema in Hadoop is the one the mapper decides to follow.
This mapping function operates under the MapReduce paradigm, described as "a software framework for easily writing applications that process large amounts of data (multi-terabyte datasets) in parallel across large clusters (thousands of nodes) of basic hardware, in a reliable and fault-tolerant manner . It basically involves mapping a given function to different inputs, i.e. a dataset or a file, and then reducing the different outputs to one. Mathematically, a MapReduce function can be expressed as follows in a multiplication table:
C = AB = A ⊕ .⊗ B
In the notation above, ⊗ corresponds to an approximation of the mapping assigned to each pair of inputs, and ⊕ corresponds approximately to the reduction function applied to the outputs. When calculations are performed on database analysis systems, a table read function is generated corresponding to the matching operations, followed by a table write function used to reduce the operation at a single exit. This two-step technique is at the heart of all the processing magic of a data lake system built on this paradigm. The result of this technique is the great flexibility it brings to a file storage system, essentially freeing it from any real need for schema,
However, due to the difficulty of maintaining and scheduling such clusters of parallel nodes, many IT teams have moved away from directly using MapReduce for big data processing. For most data engineers and developers, the new champion in town is called Apache Spark , which is described as “a unified analytics engine for large-scale data processing.” Spark can work as a standalone application or as an add-on to Hadoop YARN, where it can read data directly from HDFS. This open source solution now has one of the largest communities of developers in the world contributing to the project. Most big data cloud services offer Spark as a managed solution, like Databricks , Google Cloud's Dataproc, or Amazon 's EMR Step API .
When dealing with a big data environment, the flexibility of these frameworks for handling large and often unstructured or polymorphic files is what makes data lake a more suitable solution. By allowing data to be stored without schema constraints, the same data set can adapt to a wide range of analyzes and use cases, which is precisely what data mining needs when it comes to search for new models in analysis.
Moreover, data lakes and data warehouses are not mutually exclusive. In fact, they are mostly inclusive and complementary. An ETL tool can be designed in the post-processing phase of data lake processes in order to be redirected to a data warehouse. The latter remains important for controlled reporting and analysis, especially for descriptive or diagnostic dashboards. It is therefore important to jointly develop these two environments in the current data management and business intelligence strategy. You should not plan to choose one over the other. Instead, plan to tie the two together to get the best value for your business. Of course,
If you want to learn more about what a data lake is, read our in-depth article on the subject .