


WHAT YOU WILL LEARN IN THIS ARTICLE
- The vocabulary and key terms surrounding data lakes, as defined by data science industry experts.
- The main use cases of data lakes, as well as the challenges for business intelligence teams.
- Important considerations when implementing a data lake within an organization.
WHY SHOULD BUSINESSES CARE ABOUT DATA LAKES?
According to Gartner, companies use no more than one percent of their data for decision making and analytics. It's not because they choose to ignore the other 99% of their data. Rather, it's because most companies don't know how to access and process their own data to extract its full potential. As mentioned in our article on Omnichannel AI , 54% of respondents to an Emarketer survey said their biggest barrier is the inability to analyze and make sense of their data. As a result, companies make many decisions based on a very incomplete picture of reality.
Building a data lake is a great first step to discovering new opportunities as well as unforeseen threats. If your organization doesn't yet have a data lake, now has never been a better time to consider creating one. Data is becoming one of the most important strategic assets a business can use to drive growth and attempt to predict the future, especially in this highly unpredictable post-COVID-19 era. In fact, poor analytics exploitation could leave millions of dollars lying under your data .
Based on both professional customer experience and extensive academic research, this in-depth article will give you a better understanding of what a data lake is and how it can be implemented by your organization. Our goal is above all to offer the professional analytics and IT community a solid conceptual foundation and practical advice to help you start your data lake project.
FROM DATA WAREHOUSING TO DATA LAKES
In the early 2000s, with increasing data collection requirements, relational databases alone could no longer cope with the size and diversity of data stored by many businesses and organizations. Therefore, the establishment of data warehouses and dimensional analysis models, especially online analytical processing (OLAP), emerged as a more suitable framework for business intelligence teams.
The multidimensional modeling needs of data warehousing in turn produced functional theories from pioneers like Ralph Kimball and Bill Inmon, who provided solutions for operating these new systems from multiple data sources.
This situation has changed greatly over the past 10 to 20 years, when companies like Google, Facebook, YouTube and Amazon have seen the size and structural diversity of their data grow exponentially, necessitating sweeping changes in the Data managment. This need gave rise to frameworks like Hadoop , as well as MapReduce (dating back to Google 's research paper published in 2004) and eventually Apache Spark, enabling better solutions for large data infrastructures. As big data has continued to grow and data management issues have spread to more businesses and organizations, it has given rise to a new phase in the evolution of file storage systems. , in the form of data lakes. These ecosystems could accommodate not only structured data, but also polymorphic data structures, also known as semi-structured and unstructured data.
WHAT IS A DATA LAKE?
As we will demonstrate later in the article, the main use cases and implementation challenges surrounding the creation of a data lake are increasingly well documented. However, confusion persists about the topology of the data lake itself. First, is there a clear definition of what a data lake is? Unlike data warehouses, the structural definition of which is well established by the work (and debate) of Kimball and Inmon, reaching consensus on the functional definition of a data lake is more difficult. For the most part, the concept emerged organically based on industry needs.
The most common interpretation is probably that of James Dixon, founder and former technical director of Pentaho. Dixon is the one who coined the term “Data Lake” in 2010 and whose definition is among the most quoted in the industry. According to Dixon, a data lake can be described as follows in relation to a data store:
“Let's compare a data store to a bottled water store. The water there is treated, conditioned and structured to be consumed more easily. The content of the data lake is similar to a lake from which various users can make observations, dive or take samples. »
Another somewhat more structured definition was offered during a debate between Tamara Dull and Anne Buff, available on the popular analysis site Kdnuggets.com . The definition used during the debate was as follows:
“A data lake is a storage repository that contains a vast amount of raw data in its native format, including structured, semi-structured, and unstructured data. The data structure and requirements are not defined until the data is required. »
In the scientific literature, Snezhana Sulova from Varna University of Economics (Computer Science Faculty) presented an interpretation of data lake in an article that describes it more as a data storage strategy. Another couple of PhD researchers, Cédrine Madera and Anne Laurent, have also contributed to an elaborate technical definition of the data lake as a new step in the evolution of information architecture for management support systems. decision. The article by Cédrine Madera and Anne Laurent meticulously reviews a large number of fundamental properties associated with data lakes. However, since their definition was written in the early years of the Hadoop and MapReduce frameworks, the primary method of data processing they associate with data lakes is strictly limited to batch loading techniques. Today, this method is obviously wrong, because it does not take into account more recent advances in real-time streaming, such as with Apache Spark, Kafka, Google's Pub/Sub or Apache Beam. These have become a fundamental component of the evolution of data lakes in recent years. Real-time streaming has contributed to the explosion in the size of data collection, in particular by simplifying the integration of sensor data from IoT (Internet of Things) devices. because it does not take into account more recent advances in real-time streaming, such as with Apache Spark, Kafka, Google's Pub/Sub or Apache Beam. These have become a fundamental component of the evolution of data lakes in recent years. Real-time streaming has contributed to the explosion in the size of data collection, in particular by simplifying the integration of sensor data from IoT (Internet of Things) devices. because it does not take into account more recent advances in real-time streaming, such as with Apache Spark, Kafka, Google's Pub/Sub or Apache Beam. These have become a fundamental component of the evolution of data lakes in recent years. Real-time streaming has contributed to the explosion in the size of data collection, in particular by simplifying the integration of sensor data from IoT (Internet of Things) devices.
THE CONCEPT OF DATA GRAVITY
Another distinguishing feature of data lakes concerns a new theory called data gravity.. The idea was developed by Dave McCrory in 2010 which has since made its way into professional and academic literature, and has become the subject of discussion and debate at various IT conferences. McCrory developed a mathematical formula to support his theory. In summary, data gravity demonstrates that data has mass and, by extension, a gravitational pull of its own. According to McCrory, "This pull (gravitational pull) is caused by the need for services and applications to have higher bandwidth and/or lower latency access to data." In a data lake,
THE ROLE OF LAKES IN THE ANALYTICAL ECOSYSTEM
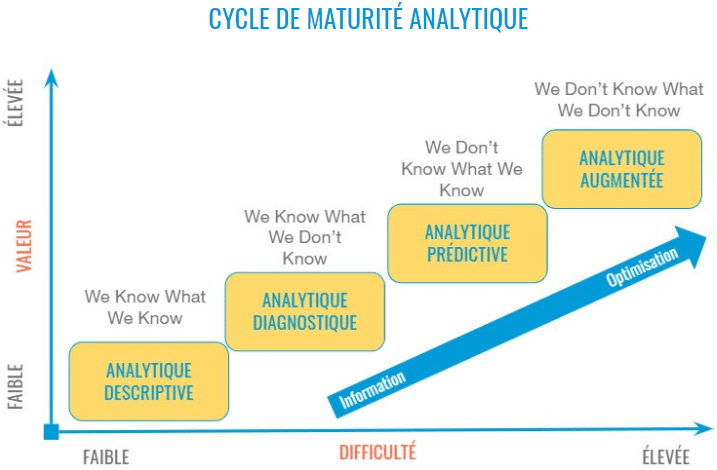
All these explanations are useful to better understand the role of the data lake in business intelligence and marketing environments. The idea would be to create a centralized database without the rigid and sometimes restrictive rules of data warehouses. Based on this definition, it might be interesting to classify the role of the data lake according to Stephen Drew's knowledge map:
-png-1.png)
Based on this model, the data lake can cover all quadrants of an organization's knowledge map, even the most complex, Quadrant 4: "What we don't know, we don't know ". Indeed, this is what massive data in the raw state has the potential to highlight within a company. This is why these lakes are very often exploited on an exploratory basis by data specialists, whose objective is the discovery of new data models, which can give rise to new commercial or marketing solutions, and above all, to identify new questions, which provides strategic value for a business intelligence or marketing team.
For a business, the choice between a data lake and a data warehouse depends on many factors, including how quickly your organization can reach analytics maturity. To learn more about the difference between data lakes and data warehouses, you can read our article on the subject: The difference between data lakes and data warehouses .
The first step for an organization is usually to master descriptive and diagnostic analytics data, which can provide a clear picture of performance. The best way to meet these needs is to set up a solid data warehouse. As the practice of analytics grows, the business can gradually transition to predictive analytics and ultimately prepare for augmented analytics (i.e. processing natural language and artificial intelligence). Each stage of maturity brings added value to the company. However, with each step comes increasing levels of complexity and technical expertise. It may therefore be a good idea to start crawling or at least try to walk before running to a more advanced analytical ecosystem.
WHAT TO DO AND WHAT NOT TO DO WITH A DATA LAKE?
If you're considering building a data lake for your organization, here's a list of best (and not-so-good) practices to keep in mind when planning your project:
TO DO
- Describe the main goals you want to achieve and the questions you want to answer with a data lake. Also note the things that you cannot currently achieve with your existing data warehouse or databases;
- Before going any further, define the analytical use cases you want to fulfill and assess the business value and their potential impact;
- Evaluate the range of data sources you will need to integrate into a data lake environment and establish a preliminary catalog of metadata.
TO AVOID
- Don't try to implement your data lake without first testing a proof of concept, such as building a "mini lake", which can be used for a single-purpose project or to address a single case of use;
- Pay attention to the promises of technology vendors and cloud providers who promise you a data lake in just a few clicks;
- Do not assign the data lake project exclusively to the IT department, marketing or a specific team. A data lake project should be a cross-functional effort and above all a team effort!
Now that we have a clearer understanding of what a data lake is and its role in the analytics ecosystem, the next step is to understand what the main use cases are and the challenges in implementing it. .
BASIC USE CASES AND CHALLENGES
In 2018, University of Agder (UiA) professor Marilex Rea Llave published an article in which she presented her point of view on the use of data lakes by business intelligence practitioners. In particular, it includes the analysis of the interactions between the members of a discussion group made up of 12 Norwegian experts in business intelligence. These experts came from various industries to try to understand the contribution of data lakes in different environments and business realities. The article gives interesting insights into the following question: What are the main use cases and implementation challenges of data lakes?
Based on interviews conducted by Llave, there are three main use cases for the data lake:
- They can be used as staging area or data source for data warehouses;
- They can be used as an experimental platform for scientists or data analysts;
- They can be used as a direct data source for self-service BI. to access atypical data.
Its analysis also identified five major challenges in implementing these lakes, including
- Data stewardship. Who is responsible for the lake and who maintains it within the organization?
- Data governance. How can we ensure the governance of a collection of data that is both massive and disparate?
- The need for human resources. What type of hiring profile should be considered to manage the infrastructure of a lake?
- Data quality. How to manage the quality of data entering the lakes given their lack of organization compared to warehouses?
- Data recovery. How to extract data from a lake to extract an analytical value? (e.g. data from IoT sensors)
All of these challenges are important to consider when designing a data lake implementation within an organization. Other authors have lists similar to Llave's, notably in an article published by Miloslavskaya and Tolstoy, in which the authors describe twelve key factors to take into account during an implementation. If you want to know more about these twelve factors, you can check out their article in the references below, at the end of this article.
A FRAMEWORK FOR DESIGNING DATA LAKES
Although the key drivers and challenges have been well described by the academics cited above, we still do not have a standardized framework for companies to address them. Unlike data warehouses, there is still no clear blueprint for designing data lakes. Probably the best effort to date can be found in a 2019 book written by Alex Gorelik called “ The Enterprise Big Data Lake: Delivering the Promise of Big Data and Data Science ”. This book provides a solid foundation that software engineers and data engineers can build on. However, it is not exactly a framework in the strict sense of the term.
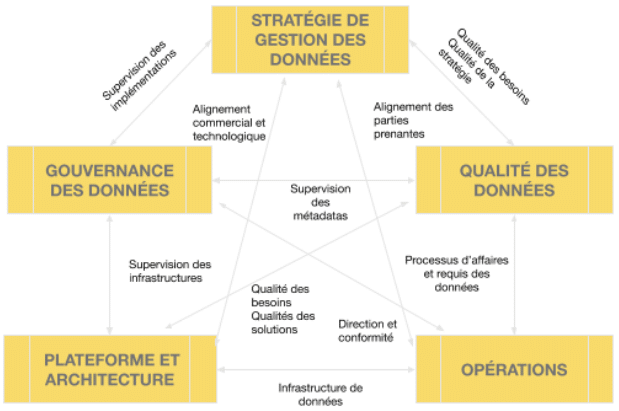
For a more comprehensive approach, a very suitable companion to Gorelix's book are the six key themes of the CMMI's Data Management Maturity Model (DMM) . This framework provides a Fortune 500 (and even NASA) tested methodology that IT and data management teams can work from when planning a large-scale project like a data lake. This is what the relationship between the six data management themes of the DMM model looks like:
THE ARCHITECTURE OF DATA LAKES: CLOUD COMPUTING OR PHYSICAL (ON-PREMISE)?
Once the business objectives, the use cases have been identified, as well as the IT management framework (i.e. the DMM), it is time to think about the type of architecture that will be deployed for the lake. This part is very important and critical for the success of the project.
Among the key decisions to be made is whether to move to the serverless “cloud” or keep everything on-premises in large data centers. Generally, organizations that have high security considerations will prefer the on-premises site, while more agile and flexible businesses will prefer the cloud. A third option is to go hybrid and mix the two together, to get the best of both worlds.
Cloud computing services are very popular these days and tend to suit many use cases and workloads. This is likely why Deloitte reports that a third (34%) of companies say they have already fully implemented cloud data modernization. In addition, 50% of companies say they are in the process of modernizing their data management.
The question is how you can make the right choice when modernizing your infrastructure or deploying new data services. And how can you make sure your data is secure? The bottom line is that each path has its own pros and cons. There is no miracle solution. Also, it's misleading to think that moving to the cloud means choosing a simple option. The cloud can certainly be simpler than a physical on-premises implementation, but that doesn't mean it's inherently simple. In fact, 47% of cloud professionals believe that complexity is the biggest risk to ROI ( Deloitte 2019) Therefore, a functional analysis of your main use cases, carried out either by your own IT team or by an external consultant, will save you a lot of headaches in the future. Data lake architectures can be very difficult to maintain and a major risk is turning your lake into a data swamp.
Additionally, if you choose to use a cloud option, as most businesses will , it's important to assess the nature and importance of the most important data sources in the business. Indeed, some cloud providers may be more suitable for certain types of data. For example, if your business is deeply invested in a Microsoft ecosystem, Azure may or may not be a better option for you. On the other hand, if your business has a strong digital marketing footprint, with lots of data coming from Google Analytics, Google Cloud might be a better fit.
Another question is how many of your data sources already have exploitable pre-existing API connections? How many sources will need a custom API solution? Which of the cloud computing providers you are considering has a partner that integrates most of the data sources or platforms used by your business? All of these questions can be answered through a well-planned functional analysis of your use cases and business needs. Ultimately, how you deal with these questions will determine "How can we store the data" or, "What can we do with all the data?"
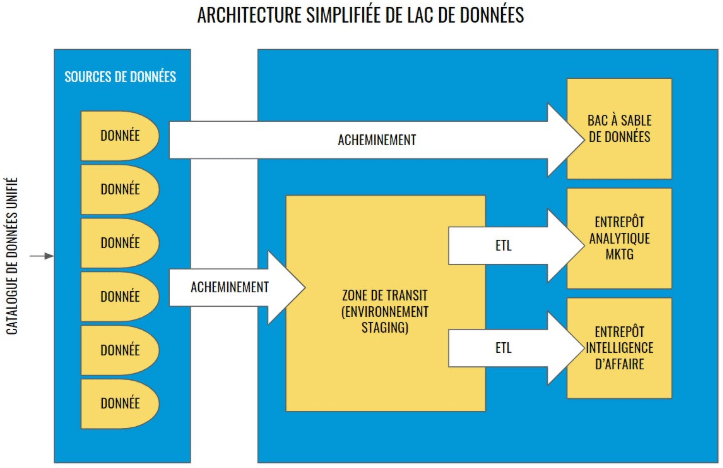
In terms of architecture, the plans vary enormously from one organization to another. However, a simplified version of a data lake architecture should include the following elements:
- A unified data catalog including all sources;
- A staging area where data will be ingested for processing before moving on to ETL work or other transformations;
- A data science sandbox for raw exploration that will generally bypass the staging area;
- One or more data warehouses dedicated to ETL jobs for business intelligence reports and/or marketing analysis.
We hope this article was helpful and gave you a better understanding of what a data lake is and what it can offer your organization. If you would like to know more about the subject or if you need help to start your project, do not hesitate to contact our data science and analysis team. In the meantime, you can go even further in your research by consulting all the bibliographical references below.
REFERENCES
- 'A Brief History of Data Lakes – DATAVERSITY', available at https://www.dataversity.net/brief-history-data-lakes/, last accessed on Feb. 24, 2020.
- 'Charting the data lake: Using the data models with schema-on-read and schema-on-write', available at https://www.ibmbigdatahub.com/blog/charting-data-lake-using-data-models- schema-read-and-schema-write, last accessed on Feb. 24, 2020.
- 'Data Gravity – in the Clouds, available at https://datagravitas.com/2010/12/07/data-gravity-in-the-clouds/, last accessed on Feb. 28, 2020.
- 'Data Lake vs Data Warehouse: Key differences', available at https://www.kdnuggets.com/2015/09/data-lake-vs-data-warehouse-key-differences.html, last accessed on Feb. 28, 2020.
- 'Data Warehouse Design – Inmon versus Kimball – TDAN.com' available at https://tdan.com/data-warehouse-design-inmon-versus-kimball/20300, last accessed on Feb. 27, 2020.
- Ahmed E., Yaqoob I., Abaker Targio Hashem I., Khan I., Abdalla Ahmed AI, Imran M., Vasilakos AV, 2017, 'The role of big data analytics in Internet of Things', Computer Networks, Volume 129, Part 2, p. 459-471.
- Dean J., Ghemawat S., 2004, 'MapReduce: Simplified Data Processing on Large Clusters', OSDI'04: Sixth Symposium on Operating System Design and Implementation, p. 137–150.
- Drew S., 1999, 'Building Knowledge Management into Strategy: Making Sense of a New Perspective', Long Range Planning, 32 (1), p.130-136.
- Khine PP, Wang ZS, 2018 [cited 2020 Feb. 19], 'Data lake: a new ideology in big data era', ITM Web Conf [Internet], ;17,03025.
- Kimball R. The data warehouse toolkit: practical techniques for building dimensional data warehouses. USA: John Wiley & Sons, Inc.; 1996.
- Llave MR, 2018, 'Data lakes in business intelligence: reporting from the trenches', Procedia Computer Science, Volume 138, p. 516-524.
- Madera C., Laurent A., 2019, 'The Next Information Architecture Evolution: The Data Lake Wave', MEDES: Management of Digital EcoSystems, HAL Id: lirmm-01399005.
- Miloslavskaya N., Tolstoy A., 2016, 'Big Data, Fast Data and Data Lake Concepts', Procedia Computer Science, Volume 88, p. 300-305.
- Shvachko K. Kuang H., Radia S., Chansler R., 2010, 'The Hadoop Distributed File System', IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), p. 1–10.
- Sulova S., 2019, 'The Usage of Data Lake for Business Intelligence Data Analysis', Conferences of the Department Informatics, Publishing house Science and Economics Varna, Issue 1, p. 135-144.
- Walker C, Alrehamy H, 2015, 'Personal Data Lake with Data Gravity Pull'. IEEE Fifth International Conference on Big Data and Cloud Computing, p. 160–167.
- Yessad L, Labiod A. Comparative study of data warehouses modeling approaches: Inmon, Kimball and Data Vault. In: 2016 International Conference on System Reliability and Science (ICSRS). 2016. p. 95–9.