


Les lacs de données se distinguent des entrepôts de données par la façon dont sont stockées des données sans qu’il soit nécessaire de les transformer. Les lacs de données emmagasinent les données sous leur forme brute alors que les entrepôts nécessitent un filtrage rigide avant de pouvoir être collectés. De plus, les lacs de données sont capables de collecter et de stocker facilement des données de tout type.
La grille ci-dessous présente quelques-unes des principales différences entre les lacs de données et les entrepôts de données. Cet article expliquera plus en détail certaines caractéristiques importantes qui rendent les lacs de données capables de traiter de très grands volumes de données avec une vitesse et une variété élevées. Cependant, en raison de la taille et du manque d’organisation des lacs de données, la gestion de la véracité des données peut être plus difficile qu’avec les entrepôts de données traditionnels.
Grille comparative entre les lacs de données et les entrepôts de données
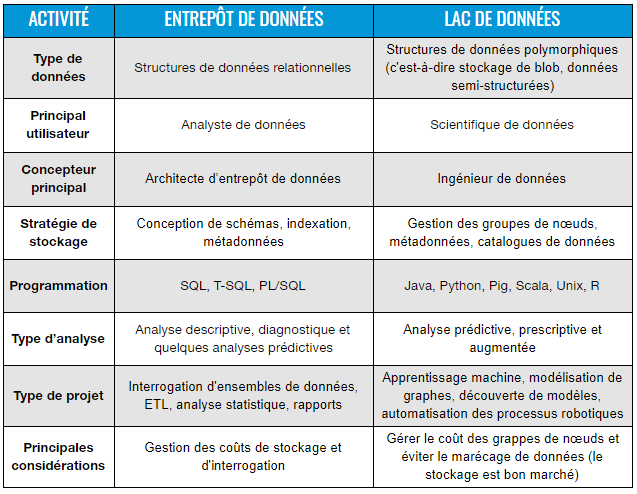
Outre les éléments de la grille ci-dessus, il existe une autre différence fondamentale entre un lac de données et un entrepôt de données, que l’on appelle la gestion des schémas. Tandis que l’entrepôt opère selon un modèle schema-on-write via des approches techniques comme l’ETL standard (Extract, Transform, Load), le lac opère quant à lui selon un modèle schema-on-read nommé dans le cadre de travail Hadoop. Il s’agit d’une distinction subtile, mais importante, puisqu’elle donne aux scientifiques de données la possibilité d’explorer des modèles de données bruts avec une architecture de lac de données.
Dans un entrepôt de données, si les données enregistrées dans une base de données ne correspondent pas au format du schéma construit pour une table particulière, les données sont simplement rejetées. Par exemple, en SQL, il n’est pas possible d’ajouter des données à la table sans l’avoir préalablement créée. Par conséquent, la création de la table n’est possible que si le schéma de cette dernière a été prédéfini avant le chargement effectif du jeu de données. Il en résulte que si les données sont modifiées par l’ajout de champs ou la modification du type de données, la table devra être supprimée ou rechargée afin de pouvoir tenir dans la base de donnée.
Cette approche classique de schema-on-write est gérable pour des ensembles de données relativement petits ou lorsqu’elle n’implique pas de clés étrangères affectant un grand nombre de tableaux. Toutefois, lorsqu’il s’agit de clés étrangères et de jeux de données de plusieurs téraoctets, le dépôt ou le rechargement de tables peut prendre des jours au lieu de quelques minutes, tout en occasionnant des coûts de calcul importants. Heureusement, les solutions modernes basées sur le cloud computing comme BigQuery et Amazon Redshift ont radicalement amélioré la puissance de calcul de l’entreposage des données. Néanmoins, pour les cas d’utilisation nécessitant des transactions ACID (atomicité, cohérence, isolation, durabilité) avec un temps de réponse de quelques millisecondes, même le puissant moteur d’interrogation de BigQuery ne suffit pas. De plus, ce dernier nécessite un traitement schema-on-write de vos tables.
Avec l’approche « schéma sur lecture », il n’y a pas de conditions préalables au chargement de fichiers de toutes sortes dans un lac de données. En fait, dans le cadre de Hadoop, qui est aujourd’hui principalement géré dans des magasins d’objets cloud sans serveur comme Google Cloud Storage, S3, etc., le processus commence par le chargement d’un ensemble de données sans aucune modification. La ligne de code ci-dessous est un exemple de commande HDFS (Hadoop Distributed File System) pour charger des données dans l’équivalent d’une table standard dans un environnement Hadoop :
hdfs dfs-copyFromLocal /temp/mktgfile*.txt
/user/hadoop/analytics
La ligne de commande ci-dessus est une instruction en Python pour extraire tous les fichiers texte qui commencent par mktgfile dans le dossier temp dans le système HDFS. Cette commande initiera tout un processus de cartographie et de distribution en arrière-plan pour optimiser le stockage selon le cadre Hadoop. De là, aucun schéma n’est nécessaire pour aller de l’avant et interroger directement ces données à partir du tableau. En Python, voici à quoi cette requête pourrait ressembler :
hadoop jar Hadoop-streaming.jar
-mapper analytics-mapper.py
-reducer analytics-reducer.py
-input /user/hadoop/analytics/*.txt
-output /user/hadoop/output/query1
Pour gérer Hadoop à plus grande échelle, YARN (Yet Another Resource Negotiator) a été créé comme une couche de gestion des ressources en grappe, qui est utilisée pour l’allocation des ressources et la planification des tâches. YARN a été introduit dans la version 2.0 de Hadoop et sert de couche intermédiaire entre HDFS et un cadre de traitement appelé MapReduce, que nous allons décrire dans un instant.
Ce qu’il est important de retenir, c’est que dans cet univers NoSQL, la structure des données n’est interprétée qu’une fois qu’elle est lue, ce qui est au cœur de l’idée du schema-on-read. Par conséquent, si un fichier d’analyse particulier ne respecte pas la structure d’un schéma prédéfini, comme par exemple si un champ est ajouté ou supprimé dans une table, la fonction de mappage dans la requête ci-dessus s’ajustera à la volée. En effet, le schéma de données dans Hadoop est celui que le cartographe décide de suivre.
Cette fonction cartographique fonctionne selon le paradigme MapReduce, décrit comme « un cadre logiciel permettant d’écrire facilement des applications qui traitent de grandes quantités de données (ensembles de données de plusieurs téraoctets) en parallèle sur de grandes grappes (des milliers de nœuds) de hardware de base, d’une manière fiable et tolérante aux pannes ». Il s’agit essentiellement de mettre en correspondance une fonction donnée avec différentes entrées, à savoir un ensemble de données ou un fichier, puis de réduire les différentes sorties à une seule. Mathématiquement, une fonction MapReduce peut être exprimée comme suit dans un tableau de multiplication :
C = AB = A ⊕.⊗ B
Dans la notation ci-dessus, ⊗ correspond à une approximation de la cartographie attribuée à chaque paire d’entrées, et ⊕ correspond approximativement à la fonction de réduction appliquée aux sorties. Lorsque les calculs sont effectués sur des systèmes d’analyse de bases de données, une fonction de lecture de table est générée en correspondance avec les opérations de mise en correspondance, suivie d’une fonction d’écriture de table utilisée pour réduire l’opération à une seule sortie. Cette technique en deux étapes est au cœur de toute la magie de traitement d’un système de lac de données construit sur ce paradigme. Le résultat de cette technique est la grande flexibilité qu’elle apporte à un système de stockage de fichiers, le libérant essentiellement de tout besoin réel de schéma, par opposition à son homologue traditionnel de base de données relationnelle.
Cependant, en raison de la difficulté de maintenir et de programmer de tels groupes de nœuds parallèles, de nombreuses équipes informatiques ont renoncé à utiliser directement MapReduce pour le traitement de données volumineuses. Pour la plupart des ingénieurs et développeurs de données, le nouveau champion en ville s’appelle Apache Spark, qui est décrit comme « un moteur d’analyse unifié pour le traitement de données à grande échelle ». Spark peut fonctionner comme une application autonome ou en complément de Hadoop YARN, où il peut lire les données directement à partir de HDFS. Cette solution open source compte désormais l’une des plus grandes communautés de développeurs au monde qui contribue au projet. La plupart des grands services de nuage de données proposent Spark comme solution gérée, comme Databricks, Dataproc de Google Cloud ou l’API EMR Step d’Amazon.
Lorsqu’il s’agit d’un environnement de données massives, la flexibilité de ces cadres pour le traitement de fichiers volumineux et souvent non structurés ou polymorphes est ce qui fait du lac de données une solution plus adaptée. En permettant de stocker les données sans contraintes de schéma, le même ensemble de données peut s’adapter à un large éventail d’analyses et de cas d’utilisation, ce qui est précisément ce dont l’exploration des données a besoin lorsqu’elle recherche de nouveaux modèles en matière d’analyse.
De plus, les lacs de données et les entrepôts de données ne s’excluent pas mutuellement. En fait, ils sont pour la plupart inclusifs et complémentaires. Un outil ETL peut être conçu dans la phase de post-traitement des processus des lacs de données afin d’être redirigé vers un entrepôt de données. Ce dernier reste important pour les rapports et les analyses contrôlés, notamment pour les tableaux de bord descriptifs ou diagnostiques. Il est donc important de développer conjointement ces deux environnements dans la stratégie actuelle de gestion des données et d’intelligence d’affaires. Il ne faut pas prévoir de choisir l’un plutôt que l’autre. Prévoyez plutôt de relier les deux ensemble afin d’obtenir la meilleure valeur pour votre entreprise. Bien entendu, vous devez établir un ordre de priorité pour votre projet de départ en fonction des besoins de l’entreprise et des capacités informatiques.
Si vous souhaitez en savoir plus sur ce qu’est un lac de données, lisez notre article de fond sur le sujet.