


Attention! Ceci est un article hautement technique afin de vous aider à implanter de l’analytique en temps réel. Nous vous conseillons de le partager avec votre équipe TI.
Avec l’essor de Kafka et d’Apache Spark, l’analyse de flux a connu une popularité croissante au cours de la dernière décennie. Au début, elle était surtout réservée à l’élite des données, à savoir les grandes organisations disposant de grandes quantités de données de streaming, comme les grandes entreprises de logiciels ou de SaaS.
Dernièrement, les fournisseurs d’infonuagique ont essayé de démocratiser l’analyse de flux en temps réel en introduisant des versions gérées d’infrastructures répandues comme Kafka, RabbitMQ, Apache Spark et Apache Beam.
Cela s’est traduit par la création de services comme Dataflow dans Google Cloud; une version gérée par Apache Beam; mais aussi PubSub, la réplique de Google aux solutions open source telles que Kafka et RabbitMQ.
L’utilisation la plus courante implique l’écriture de logs de streaming provenant de microservices utilisant une architecture Kubernetes. Disposer d’une file d’attente avec des éditeurs et des abonnés, où un microservice spécifique peut écouter des événements spécifiques, en excluant tout le bruit provenant du flux global, a changé la donne pour les ingénieurs de données.
D’un côté, les développeurs de logiciels peuvent partager des données entre les microservices plus facilement, et de l’autre côté, les environnements analytiques comme les lacs et les entrepôts de données des entreprises peuvent connecter leurs propres écouteurs d’événements, sans perturber le flux entre les différents composants opérationnels.
Pour les équipes d’analyse et de veille stratégique, cette nouvelle capacité s’est avérée extrêmement précieuse. Par le passé (et c’est souvent encore le cas), les pipelines de données pour les analyses impliquaient une opération de « lecture directe » dans des bases de données d’exploitation, comme Cassandra, Postgres ou MongoDB. Cependant, la plupart des architectes de bases de données sont réticents à l’idée d’autoriser toute connexion directe à un flux de données opérationnel, même en mode lecture. En effet, ceci pourrait se traduire par le ralentissement ou la perturbation de la base de données opérationnelle en question et avoir des conséquences catastrophiques sur les flux de travail stratégiques quotidiens.
Le système de streaming via des bus comme PubSub permet d’éliminer ce risque en grande partie, puisqu’il se connecte aux événements en direct grâce à un système d’écoute qui n’implique pas directement votre base de données opérationnelle. De plus, un flux traite les données d’un seul événement à la fois, en temps réel, et non pas par lot de plusieurs chargements coûteux.
Tout ceci est très bien, mais, il reste un problème. Ce problème, c’est JSON.
Comme la plupart des ingénieurs de données le savent, la majorité des flux utilisent des Objets JSON, qui sont par définition, les formats de données les plus coûteux à analyser. S’ils ont l’avantage d’être très flexibles, ils causent en revanche des ralentissements sur les flux de travail qui les utilisent. Des solutions ont été créées pour pallier ces problèmes de vitesse; notamment simdjson 0.3, une version mise à jour de SIMD publiée par Dr Daniel Lemire, mon directeur de thèse, en 2019. Vous pouvez consulter Github pour plus de renseignements sur cette solution.
Ceci étant dit, même avec de tels outils, dans le contexte des flux de travail d’analyse, les flux en direct JSON causent un défi de taille aux ingénieurs de données : les défaillances du schéma.
Comme nous le savons, les bases de données analytiques sont très différentes des bases de données de logiciels. Elles ont des objectifs différents et donc des architectures différentes. Les bases de données d’analyse « dénormalisent » vos données pour permettre un stockage moins coûteux. Ces deux types de bases de données ont cependant un point commun, elles ont besoin de vos données afin de suivre des schémas stricts et des règles prévisibles.
Le problème c’est que les logs d’événements JSON ont souvent été conçus de manière à ne pas suivre de règles strictes, mais au contraire, à être flexibles et à contourner ces règles.
Par conséquent, créer un pipeline de données pour une grande quantité de données hétérogènes en format JSON peut devenir un véritable cauchemar. Comment je le sais? Je l’ai vécu!
Avec l’utilisation d’une infrastructure comme Apache Beam pour envoyer vos données de streaming à un entrepôt comme BigQuery, il est nécessaire d’élaborer des règles « what if » dans votre code Java ou Python de manière à anticiper les potentielles variations qui pourraient se produire, et qui pourraient entraver votre schéma et donc votre pipeline.
Dans la plupart des cas, si les développeurs de logiciels n’ont pas de règles dans un catalogue de données clair, ce qui est souvent le cas, les développeurs et les ingénieurs doivent mettre en place des règles de manière itérative. Malheureusement, « itératif » signifie souvent laisser son pipeline échouer, le réparer et le redémarrer, encore et encore.
Si vous avez plus d’expérience, vous évitez ces problèmes. Comment? En créant une étape intermédiaire appelée un lac de données, dans lequel vous pouvez stocker vos données « sales ». Vous pouvez alors créer votre pipeline de flux de données en utilisant deux routes : 1) une route avec vos données « connues » et vos schémas établis et 2) une route « try-catch » pour repérer les exceptions détectées par votre code de pipeline, qui redirige ensuite ce flux « sale » vers un autre lac temporaire. Dans Google Cloud, vous pouvez également utiliser des outils comme Cloud Monitoring ou configurer un système d’alerte en utilisant Google Functions. Les données « sales » de votre lac peuvent alors être examinées, corrigées et renvoyées vers votre entrepôt de données « propres », ou comme certains l’appellent la « gold zone ».
Une autre technique consiste à regrouper votre pipeline de données dans Dataflow pour produire un tableau d’attributs de métadonnées simples (nom, ville, ID, etc.), ainsi qu’une colonne qui contient vos données utiles JSON sous forme brute. D’après mon expérience, lorsque vous êtes encore en train de profiler vos données dans la phase initiale d’un grand projet de lac ou d’entrepôt de données, qui implique des logs d’événements JSON en temps réel – surtout lorsque peu de choses sont documentées sur les données et lorsque les schémas de données sont fréquemment mis à jour – cette approche peut être très efficace. Elle peut également vous faire gagner beaucoup de temps et d’efforts dans le processus.
En intégrant vos données utiles JSON dans un tableau de données structuré sous forme de « string » avec quelques attributs de métadonnées afin de filtrer facilement les données en fonction de vos sources ou de votre logique d’affaires, vous pouvez développer un véritable flux de travail « schema-on-read » (terme d’abord introduit par Rajesh and Ramesh en 2016 pour décrire la logique du lac de données), qui transformera une partie de votre instance BigQuery en une zone de transit, ainsi qu’une zone « propre » (la « gold zone »).
Votre zone de données brutes peut être organisée sous forme de mini lacs de données à l’intérieur de votre lac. Pour en savoir plus sur les lacs de données, vous pouvez trouver mon article complet sur le sujet dans le Journal Applied Marketing Analytics, ou encore ici et ici.
Voici à quoi peut ressembler une architecture de lac de données BigQuery :
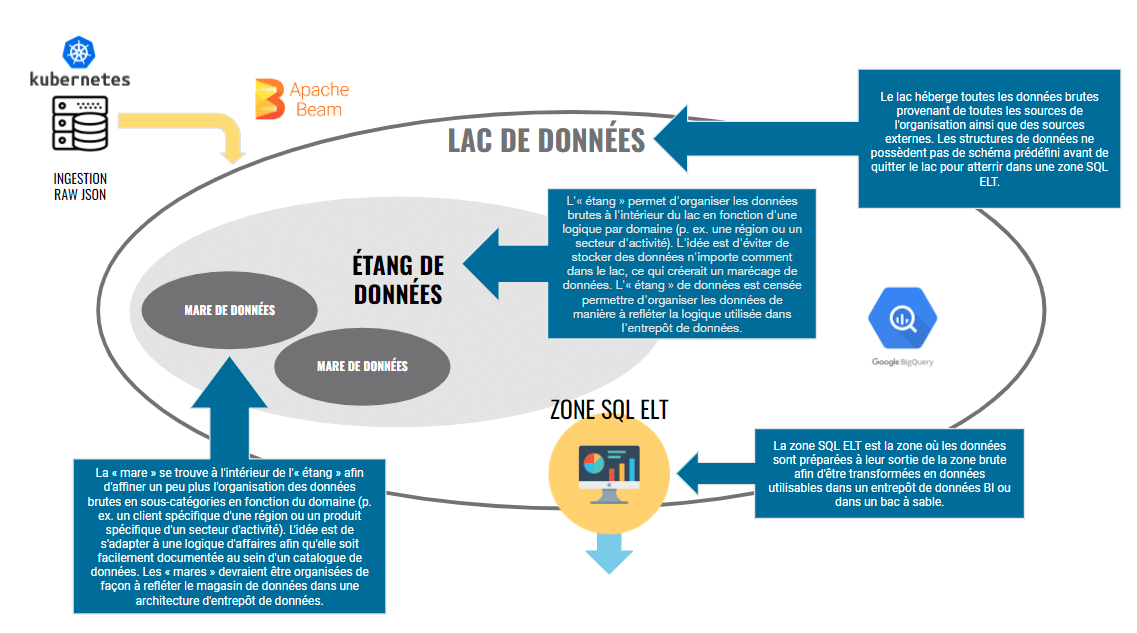
L’idée est simple : pousser le cycle final de transformation des données aussi près que possible de la consommation de rapports finale par votre équipe de BI ou d’analyse marketing pour vous permettre de créer un flux de travail ELT (Extract, Load, Transform) flexible, au lieu d’être prisonnier d’un flux de travail ETL (Extract, Transform, Load) plus rigide.
L’avantage de créer une telle architecture de flux (« schema-on-read ») dans BigQuery (ou dans Snowflake ou un quelconque entrepôt de données infonuagique) est de maintenir la flexibilité inhérente au format brut JSON. Autrement dit, travailler avec plutôt que contre.
De plus, en hébergeant les données utiles de vos Objets JSON dans un tableau BigQuery structuré et en taguant ses attributs clés, il est plus facile de contrôler la qualité qu’en stockant les données sous forme de « blob ». Il existe deux raisons à cela :
1. Vous pouvez facilement comparer les résultats des requêtes SQL entre votre nombre de lignes JSON brutes et votre sortie structurée transformée. Par exemple, si votre tableau JSON brut contient 143 943 lignes de données pour les ventes en Ontario, vous pouvez les comparer assez facilement après transformation. Pour l’avoir fait assez souvent, j’en sais quelque chose. Faire la même chose via le stockage en nuage est beaucoup, beaucoup plus compliqué.
2. Vous pouvez facilement visualiser et travailler avec les subtilités inhérentes aux données semi-structurées et des colonnes imbriquées en utilisant STRUCT() et ARRAY() pendant les requêtes SQL.
Pour examiner plus en profondeur vos Objets JSON et pour mieux comprendre des colonnes imbriquées, mon outil préféré est l’outil gratuit de JSON JSON Formatter & Validator.
Si vous ne travaillez pas souvent avec STRUCT() et ARRAY() dans BigQuery, je vous recommande de vous entraîner avec le fragment ci-dessous dans votre environnement BigQuery :
WITH superHeroes AS
SELECT '{ "squadName": "Super hero squad","homeTown": "Metro City","formed": 2016,"secretBase": "Super tower","active": true,"members": [{"name": "Molecule Man","age": 29,"secretIdentity": "Dan Jukes","powers": ["Radiation resistance","Turning tiny","Radiation blast"]}, {"name": "Madame Uppercut", "age": 39, "secretIdentity": "Jane Wilson","powers": ["Million tonne punch","Damage resistance", "Superhuman reflexes"]}, {"name": "Eternal Flame", "age": 1000000, "secretIdentity": "Unknown", "powers": ["Immortality", "Heat Immunity", "Inferno", "Teleportation", "Interdimensional travel"]}]}' AS my_json
)
-- Array + STUCT Table
SELECT
JSON_EXTRACT_SCALAR(my_json, '$.squadName') AS squadName,
JSON_EXTRACT_SCALAR(my_json, '$.homeTown') AS homeTown,
JSON_EXTRACT_SCALAR(my_json, '$.formed') AS formed,
JSON_EXTRACT_SCALAR(my_json, '$.secretBase') AS secretBase,
JSON_EXTRACT(my_json, '$.active') AS active,
ARRAY(
SELECT AS STRUCT
JSON_EXTRACT_SCALAR(m, '$.name') AS name,
JSON_EXTRACT_SCALAR(m, '$.age') AS age,
JSON_EXTRACT_SCALAR(m, '$.secretIdentity') AS secretIdentity,
ARRAY(
SELECT JSON_EXTRACT_SCALAR(p, '$') FROM UNNEST(JSON_EXTRACT_ARRAY(m, '$.powers')) AS p
) AS powers
FROM UNNEST(JSON_EXTRACT_ARRAY(my_json, '$.members'))
AS m) AS members
FROM superHeroes;
Pour plus d’explications sur les Objets JSON ci-dessus, rendez-vous ici : developer.mozilla.org
Pour en savoir plus, je vous recommande également la lecture de cet article de Deepti Garg : How to work with Arrays and Structs in Google BigQuery.
Pour les utilisateurs aguerris de BigQuery, si vous ne l’avez pas encore fait, vous pouvez contacter votre représentant Google Cloud pour accéder à la nouvelle fonctionnalité appelée BigQuery native JSON data type. Cette nouvelle capacité pourrait changer encore plus la donne en matière de traitement des flux bruts en direct d’objets JSON à même votre entrepôt de données infonuagique, ainsi que des données semi-structurées en général. Pour les utilisateurs de Google Analytics 4, le travail avec les Objets JSON et des colonnes imbriquées sera important, surtout si vous prévoyez d’utiliser PubSub pour diffuser en direct des événements de sites Web ou d’applications mobiles vers BigQuery, ce qui peut ouvrir de grandes possibilités d’analyse avancée et d’apprentissage automatique à votre organisation.
Comme toujours, si vous avez des questions ou si vous souhaitez en savoir plus sur Google Cloud et BigQuery en général, continuez à lire notre blogue ou communiquez avec notre équipe d’analytique et de science des données. Adviso est un partenaire de service Google Cloud basé à Montréal, Canada.