Nota bene: Please note that the following article is intended primarily for data engineers and IT professionals generally familiar with BigQuery and Google Cloud.
With the rise of Apache Kafka and Spark, streaming analytics has become increasingly popular over the past decade. At first it was mostly reserved for the data elites, namely those large organizations having vast amounts of streaming data, such as large software or SaaS companies.
In more recent years, cloud providers have attempted to democratize real-time streaming analytics by introducing managed versions of popular frameworks such as RabbitMQ and the Apache products Kafka, Spark and Beam.
This has resulted in services like Dataflow in Google Cloud, which is a managed version of Apache Beam, as well as Pub/Sub, which is Google’s answer to open source solutions like Kafka and RabbitMQ.
The common use cases involve streaming log events coming from microservices using a Kubernetes architecture. Having a queue with publishers and subscribers, where a specific microservice can listen to specific events, excluding all the noise coming from the overall stream, has been a game changer for data engineers.
One the one hand, software developers can communicate data between microservices more easily. On the other hand, analytics environments like enterprise data lakes and warehouses can connect their own event listeners, without disrupting the flow between operational components.
For analytics and business intelligence teams, that new capability has been extraordinarily valuable. In the past, data pipelines for analytics used to involve (and still do, in many cases) a direct “read” operation into operation databases, like Cassandra, Postgres or MongoDB. However, most database architects are very sensitive about allowing any direct connection to an operational data workflow, even in read mode, given the risk of slowing or even disrupting said operational database, which can have catastrophic consequences on daily strategic workflows.
Having a streaming system through buses like Pub/Sub eliminates that risk in large part, since the streaming system connects to live log events through a listening system that doesn’t directly involve your operational database. Moreover, a stream processes data one event at a time, in real time, as opposed to doing a series of costly batch loads.
All of that is great! However, there is a problem. That problem is called JSON.
As most data engineers know, the majority of streams use the JSON object data format, which by definition is among the most costly to parse. While it has the advantage of being very flexible, this causes most JSON-related workflows to be slow. Some solutions have been developed to optimize the speed problem, namely an upgraded version of SIMD that was released in 2019 by my thesis professor, Dr. Daniel Lemire, called simdjson 0.3. You can learn more about it on Github.
But even with such great tools, in the context of analytics workflows, live JSON streams involve another important challenge for data engineers. That challenge is called “schema failure.
As we know, analytics databases are very different from software operations databases. They serve very different purposes and, therefore, have different architectures. Analytics databases denormalize your data, since storage is cheap. Nevertheless, both database types share one thing in common: They need your data to follow strict schemas and predictable rules.
The problem is that often JSON log events were not designed to follow strict rules—they were designed for flexibility and the option of getting around rules.
As a result, creating a data pipeline for large heterogeneous data in JSON format can be a nightmare. How do I know? I’ve lived it!
When using a framework like Apache Beam to send your streaming data to a warehouse like BigQuery, you need to define elaborate “what if” rules in your Python or Java code in order to “anticipate” the likely variations that could occur, which could break your schema and, therefore, your pipeline.
In most cases, if software developers don’t have rules in a tidy data catalogue document, which is a fairly common scenario, the analytics developers and engineers have to figure out those rules iteratively. Unfortunately, “iterative” often means letting your pipeline fail, then fixing it, then restarting it… over and over again.
If you have more experience, you avoid doing that. How? By creating an intermediate staging ground called a data lake, where you can store your dirty data. From there, you create your Dataflow pipeline using two routes: 1) a route with your “known” rules and established schemas and 2) a route to “try-catch” all exceptions detected by your pipeline code, which then reroutes this “unclean” stream into another staging lake. In Google Cloud you can also use tools like Cloud Monitoring or set up an alert system using Cloud Functions. The dirty data in your lake can be examined, cleaned, then sent back to your clean or, as some call it, “gold zone” of your data warehouse.
Another technique is to package your data pipeline in Dataflow to produce a table of simple metadata attributes (name, city, ID, etc.), along with a column that contains your actual JSON payload in raw form. In my experience, when you’re still profiling your data in the early phase of a large data lake or warehouse project, which involves real-time JSON log events, especially when little is documented about the data and when data schemas are frequently updated, this approach can be very effective. It can also save you a lot of time and effort in the process.
By ingesting your JSON payload inside a data table structured as a “string” type, along with a few metadata attributes to easily filter based on your sources or business logic, you can develop a true “schema-on-read” workflow (a term first introduced by Rajesh and Ramesh in 2016 to describe the data lake logic), which in essence will turn a portion of your BigQuery instance into a staging area, with another section turned into a “gold” or clean zone.
Your raw zone can be organized into what are called “data ponds” inside your data lake. To learn more about data lakes in general, please read my detailed article on the subject in the Journal of Applied Marketing Analytics or my other articles here and here.
In essence, you can see below what BigQuery data lake architecture could look like:
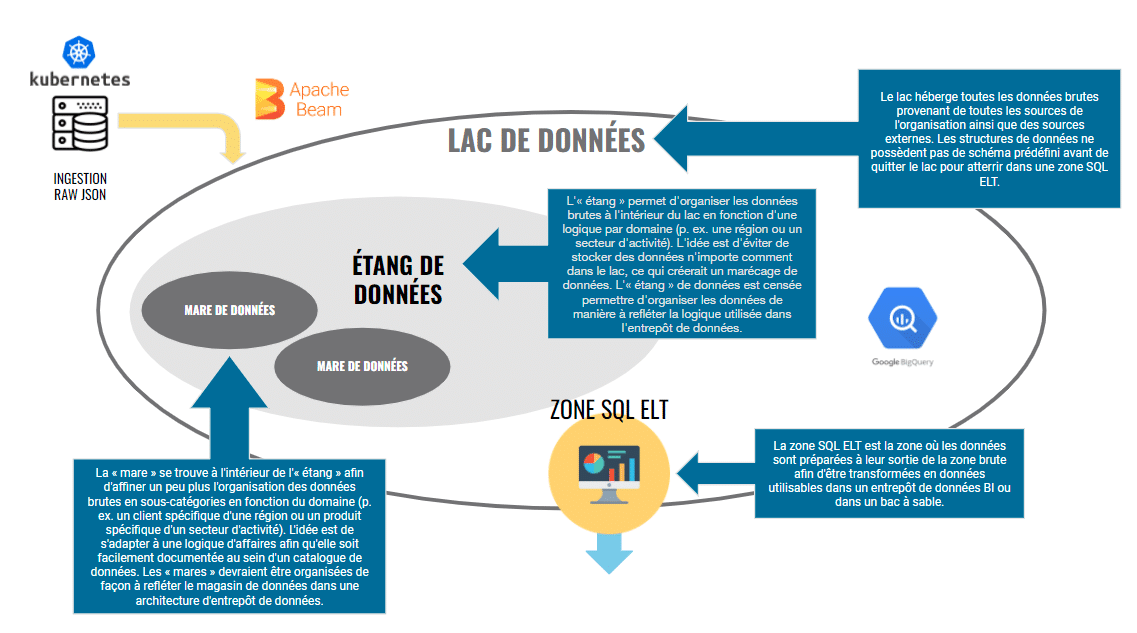
The key idea is simple: Push the final data transformation cycle as close as possible to the final reporting consumption by your BI or marketing analytics team. This will allow you to create a flexible ELT (extract, load, transform) workflow, as opposed to being trapped into a more rigid ETL (extract, transform, load) workflow.
The advantage of building such a streaming schema-on-read architecture in BigQuery (or Snowflake or any other cloud data warehouse) is to maintain the inherent flexibility of your raw JSON. Embrace it instead of fighting it.
Furthermore, by housing your JSON objects payload into a structured BigQuery table and tagging its key attributes, it’s easier to do quality control than if you load the data in Cloud Storage as a blob. The reason is (at least) twofold:
1. You can easily compare SQL query results between your raw JSON row count and your transformed structured output. For example, if your raw JSON table has 143,943 rows of data for Ontario sales, you can benchmark them rather easily after transformation. I should know—I’ve done it quite often. Doing the same thing via Cloud Storage is much, much more complicated, not to mention slow since you’re using a federated query.
2. You can easily visualize and work with the inherent subtleties of semi-structured data and nested fields using STRUCT() and ARRAY() during SQL queries.
To further examine your JSON objects and to get a better understanding of nested patterns, my favourite tool is the free JSON Formatter & Validator.
If you’re not familiar with how to work with STRUCT() and ARRAY() inside BigQuery, I recommend you practise with the snippet below inside your own BigQuery environment:
WITH superHeroes AS
SELECT '{ "squadName": "Super hero squad","homeTown": "Metro City","formed": 2016,"secretBase": "Super tower","active": true,"members": [{"name": "Molecule Man","age": 29,"secretIdentity": "Dan Jukes","powers": ["Radiation resistance","Turning tiny","Radiation blast"]}, {"name": "Madame Uppercut", "age": 39, "secretIdentity": "Jane Wilson","powers": ["Million tonne punch","Damage resistance", "Superhuman reflexes"]}, {"name": "Eternal Flame", "age": 1000000, "secretIdentity": "Unknown", "powers": ["Immortality", "Heat Immunity", "Inferno", "Teleportation", "Interdimensional travel"]}]}' AS my_json
)
-- Array + STUCT Table
SELECT
JSON_EXTRACT_SCALAR(my_json, '$.squadName') AS squadName,
JSON_EXTRACT_SCALAR(my_json, '$.homeTown') AS homeTown,
JSON_EXTRACT_SCALAR(my_json, '$.formed') AS formed,
JSON_EXTRACT_SCALAR(my_json, '$.secretBase') AS secretBase,
JSON_EXTRACT(my_json, '$.active') AS active,
ARRAY(
SELECT AS STRUCT
JSON_EXTRACT_SCALAR(m, '$.name') AS name,
JSON_EXTRACT_SCALAR(m, '$.age') AS age,
JSON_EXTRACT_SCALAR(m, '$.secretIdentity') AS secretIdentity,
ARRAY(
SELECT JSON_EXTRACT_SCALAR(p, '$') FROM UNNEST(JSON_EXTRACT_ARRAY(m, '$.powers')) AS p
) AS powers
FROM UNNEST(JSON_EXTRACT_ARRAY(my_json, '$.members'))
AS m) AS members
FROM superHeroes;
You can access the above JSON with more explanations by going on developer.mozilla.org.
For further reading, I also recommend you start with this great article by Deepti Garg called How to work with Arrays and Structs in Google BigQuery.
For more advanced BigQuery users, if you haven’t done so already, you should reach out to your Google Cloud rep to access the new feature called BigQuery native JSON data type. This new capability could be an even bigger game changer for handling raw live streams of JSON objects directly from your cloud data warehouse, as well as semi-structured data in general. For Google Analytics 4 users, working with JSON objects and nested fields will become important soon, especially if you plan on using Pub/Sub to live-stream website or mobile applications events to BigQuery, which can open up great opportunities for advanced analytics and machine learning in your organization.
As always, if you have any questions or would like to learn more about Google Cloud and BigQuery in general, continue reading our blog or reach out to our Analytics and Data Science team. Adviso is a Google Cloud Service Partner operating out of Montreal, Canada.








