


Les fonctions traditionnelles des outils de mesure en analytics
À travers les années, les outils de mesure en analytics sont devenus omniprésents. En fait, il est maintenant très rare qu’un site web n’en utilise aucun. On retrouve Google Analytics en figure de proue, qui a jouit d’une forte adoption grâce à la performance et la gratuité de ses solutions. Beaucoup des marketeurs utilisent fréquemment ces données pour guider leurs décisions marketing ou pour vérifier la performance de campagnes, par exemple.
Lorsqu’un marketeur pense à un outil de mesure, il a probablement en tête des graphiques et des tableaux qui aident à mieux comprendre le comportement du consommateur. Toutefois, derrière ces tableaux et graphiques se trouvent une innombrable quantité de données recueillies par ces outils! Ces données sont généralement rendues disponibles par API par les fournisseurs de service, comme Google Analytics et Adobe Analytics, pour ne nommer que ceux-ci.
Cet accès à la donnée brute est d’une grande valeur pour les organisations puisqu’elle peut mieux répondre à des questions importantes en marketing telles que la prévision des ventes par exemple. En effet, plusieurs de ces questions ne peuvent trouver réponse directement à l’aide d’un outil de mesure. C’est à ce moment que le traitement des données à l’aide d’outils et de langages de programmation statistique prennent tout leur sens.
Que peut-on accomplir avec des données analytics en programmation statistique?
Dans cet article, deux cas d’utilisation seront mis de l’avant : le premier cas que je vous propose est celui de la prévision (forecasting) des sessions sur un site web. Le deuxième présentera une approche de segmentation des visiteurs en se basant sur les données de navigation des usagers. Pour les intéressés, le code R complet pour reproduire les exemples qui suivront est disponible à la fin de l’article.
À titre informatif, les données utilisées dans ce contexte proviennent de Google Analytics et seront traitées à l’aide du langage de programmation R pour ses fortes capacités en analyse statistique. À noter que, l’analyse peut aussi être faite avec Adobe Analytics ou Segment, par exemple.
1. Prévision des sessions sur un site web
Pour permettre de créer un modèle de prévision d’une série chronologique, vous devez en premier lieu générer un fichier de données. Pour ce faire, plusieurs packages R permettant de recueillir directement les données disponibles. Je vous recommande l’utilisation de googleAnalyticsR de Mark Edmondson.
Une fois que vous avez votre fichier de données, vous pourrez commencer un processus visualisation des données, qui vous permettra de mieux comprendre l’évolution des sessions sur votre site web.
Code R pour créer votre fichier de données
library(googleAnalyticsR)
View_id <- XXXXXXXX # Le view ID est situé dans votre compte Google Analytics
date_debut_forecast <- "2013-01-01"
date_fin_forecast <- "2018-12-31"
metriques_forecast <- c("ga:sessions")
dimensions_forecast <- c("ga:yearmonth")
# Appel à Google Analytics pour la création du fichier de données
ga_forecast <- google_analytics(view_id, date_range = c(date_debut_forecast, date_fin_forecast),
metrics = metriques_forecast,
dimensions = dimensions_forecast)
# Formatage du data.frame en time series
ga_forecast1 <- dcast(ga_forecast,
yearmonth ~ .,
value.var = "sessions")
rownames(ga_forecast1) <- ga_forecast1$yearmonth
ga_forecast1$yearmonth = NULL
ga_forecast2 <- ts(ga_forecast1, frequency=12)
# Visualisation des sessions sur le site web
plot(ga_forecast2)
Session sur le site lors des 7 dernières années
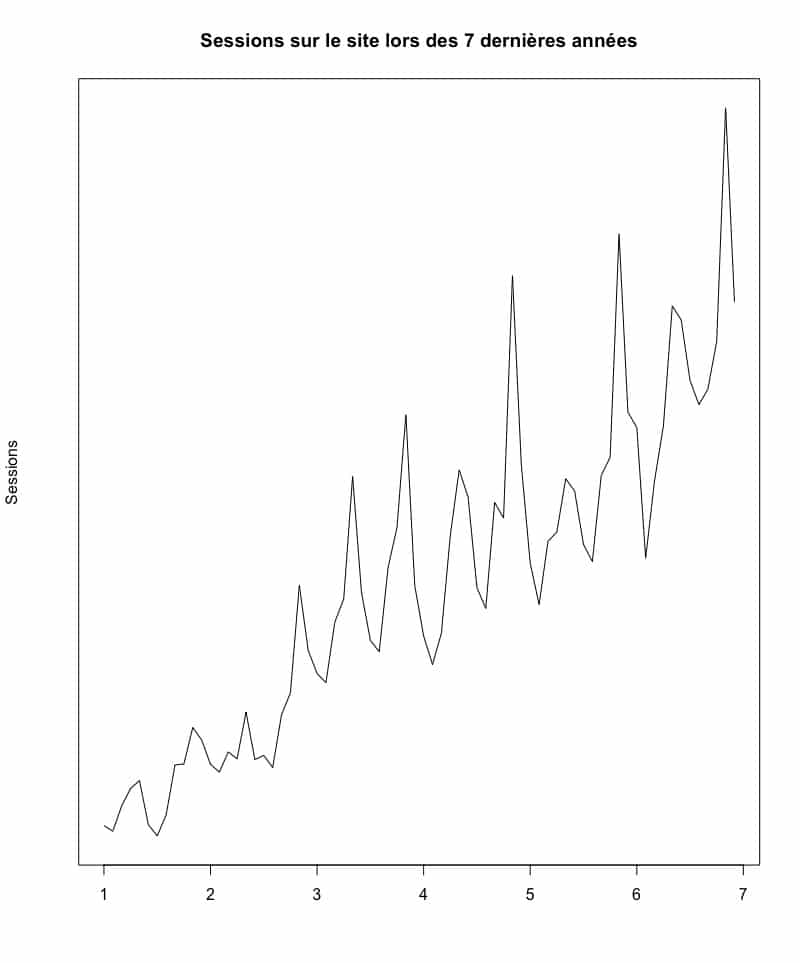
En analysant le graphique ci-haut, on remarque d’abord que le nombre de sessions semble avoir connu une évolution constante dans les sept dernières années. En d’autres mots, il semble que la tendance de croissance des sessions soit constamment à la hausse. Vous pourrez remarquer assez distinctement des sommets et des vallées à intervalles réguliers dans l’évolution des sessions. On pourrait donc déduire qu’il y a une certaine saisonnalité dans les sessions sur ce site web. Vous pouvez faire l’analyse de la tendance et de la saisonnalité de façon précise en utilisant une méthode de décomposition de notre série chronologique. À l’aide de quelques lignes de code R, vous pourrez ainsi analyser la décomposition.
Code R pour décomposer votre série chronologique
# Décomposition de la série en tendance et saisonnalité
forecast_decomp <- decompose(ga_forecast2)
plot(forecast_decomp)
Décomposition de notre série chronologique
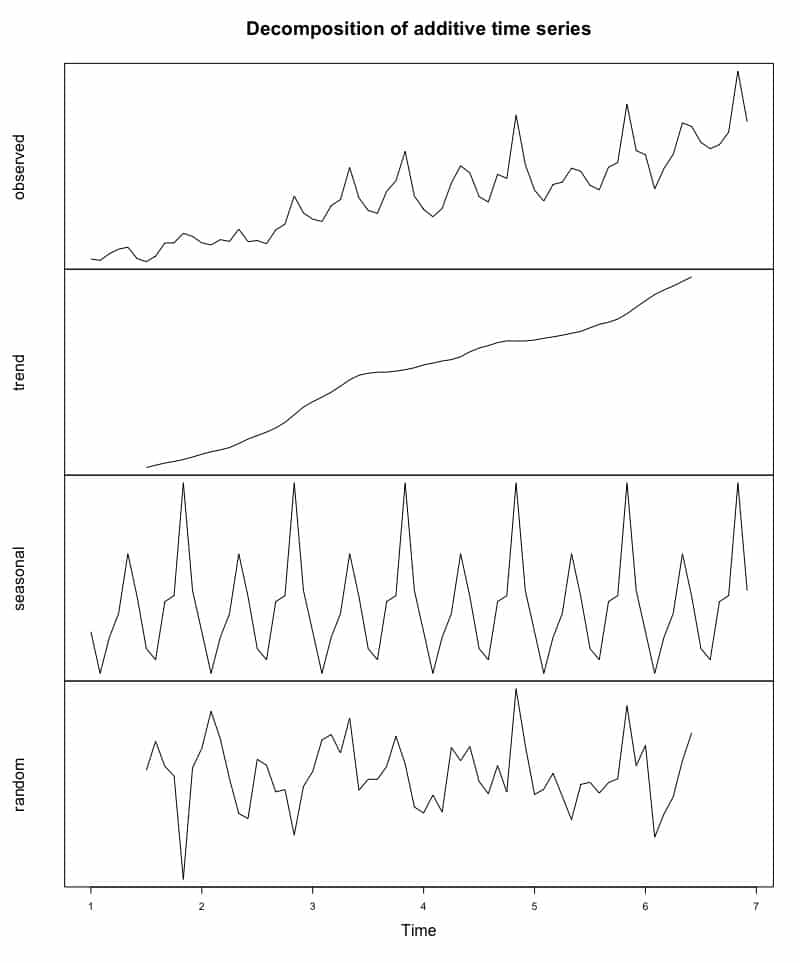
Notre lecture de la situation était donc juste :
- En effet, en regardant la deuxième courbe, soit celle de la tendance, on peut confirmer que celle-ci est relativement constante au courant des sept dernières années.
- Pour ce qui est de la troisième courbe, on constate une forte saisonnalité qui est facile à identifier. Dans ce cas, il semble que les mois de mai et de novembre sont des mois fastes en termes de sessions sur ce site web. À l’opposé, les mois de février et juillet sont les mois ayant constamment un nombre de sessions plus bas par rapport aux autres mois d’une même année.
Maintenant que vous avez une meilleure compréhension de la série chronologique et des données, vous pouvez créer un modèle de prévision des sessions pour les années à venir. Le package R du nom de “forecast”, créé par le statisticien australien Rob J. Hyndman, permet de facilement créer un modèle de prévision de série chronologique ainsi que de visualiser cette prévision sur un graphique. Voici donc un exemple de prévision des sessions sur un site web pour les deux prochaines années.
Code R pour la prévision
# Forecasting des sessions sur le site web
ga_forecast3 <- msts(ga_forecast2, seasonal.periods = c(12))
forecasting <- tbats(ga_forecast3)
forecasting2 <- forecast(forecasting)
plot(forecasting2)
Prévision des sessions sur le site lors des deux prochaines années
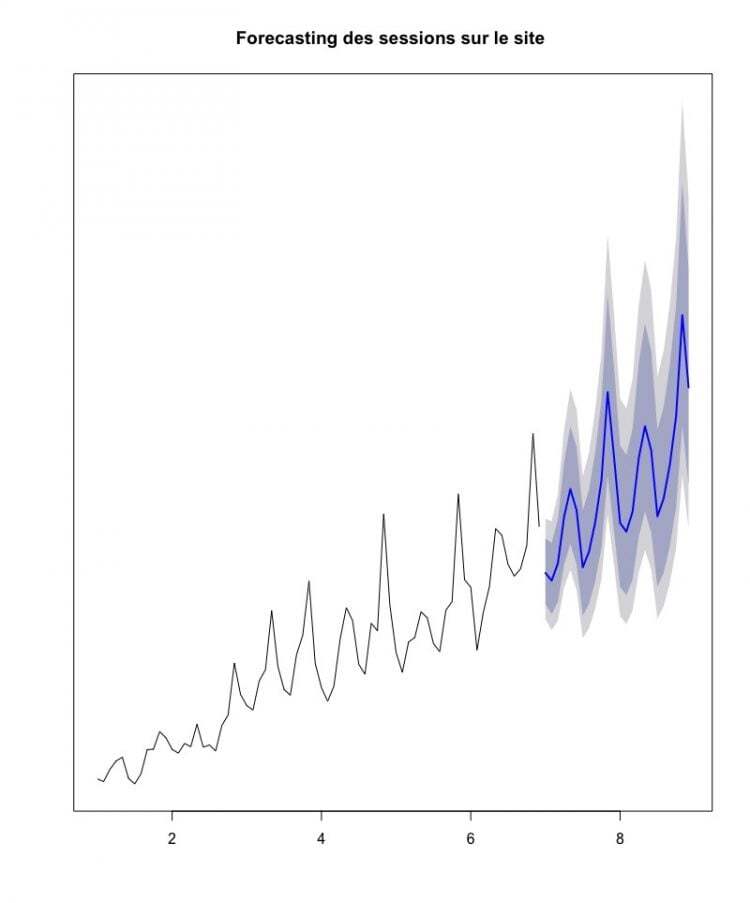
La ligne bleue représente la prévision, alors que les zones colorées représentent l’intervalle de confiance (à 80% en foncé et 95% en pâle) de notre modèle de prévision. Si notre modèle est juste, il semble que les sessions continueront de croître pour les prochaines années.
2. Segmentation non supervisée
Les entreprises ont généralement une certaine définition de leurs cibles, même que plusieurs utilisent les personas pour rendre plus concrète la définition de celles-ci. Une des limitations potentielles des personas provient du fait qu’il s’agit souvent d’une interprétation plus ou moins arbitraire de qui est notre cible. Pour ajouter un certain niveau de précision, il existe également des outils statistiques qui permettent de calculer l’homogénéité d’un groupe d’individu en prenant en compte de variables. Pour y arriver, je vous propose d’utiliser les données de navigation d’un site pour tenter de définir des groupes y navigants d’une façon similaire.
Tout comme dans le premier cas d’utilisation, il faudra commencer par créer le fichier de données. Pour ce faire, vous devrez commencer par recueillir les données de navigations des utilisateurs de votre site sur une période d’un an. Vous pouvez utiliser plusieurs variables et faire des test pour découvrir quels sont les variables les plus pertinentes. À des fins d’exemples, voici les variables que j’utiliserai dans ce cas :
- nombre de sessions dans une année,
- le nombre de hits,
- le nombre de page vues,
- le nombre de page produits vues,
- le temps moyen passé sur une page,
- le nombre de transactions,
- la durée moyenne des sessions,
- le nombre rebond,
- le nombre de pages vues en moyenne par session.
La première chose que vous voudrez voir est si l’ajout de segments tend à rendre vos groupes plus homogènes. Pour y arriver, portez attention à votre analyse de regroupement. Vous cherchez en fait à trouver un équilibre entre la précision et la facilité d’interprétation. Suite à la création du fichier de données et l’analyse de la somme des erreurs, vous obtiendrez le graphique suivant le bloc de code ci-dessous.
Code R pour créer un fichier de données pour la segmentation
view_id <- XXXXXXXX
date_debut <- "2018-01-01"
date_fin <- "2018-12-31"
metriques_segmentation <- c("ga:sessions", "ga:hits", "ga:pageviews","ga:productDetailViews", "ga:timeOnPage", "ga:transactions", "ga:sessionDuration","ga:bounces", "ga:pageviewsPerSession")
dimensions_segmentation <- c("ga:dimension10")
# Appel à Google Analytics
ga_segmentation <- google_analytics(view_id, date_range = c(date_debut, date_fin), metrics = metriques_segmentation, dimensions = dimensions_segmentation)
# Préparation du fichier de données pour l'analyse de segmentation
segmentation <- na.omit(ga_segmentation)
segmentation2 <- scale(segmentation1)
# Identifier le nombre de segments
within_sum_square <- (nrow(segmentation2)-1)*sum(apply(segmentation2,2,var))
for (i in 2:15) within_sum_square[i] <- sum(kmeans(segmentation2, centers=i)$withinss)
# Visualisation
plot(within_sum_square, type = "b")
Sélection du nombre de segments
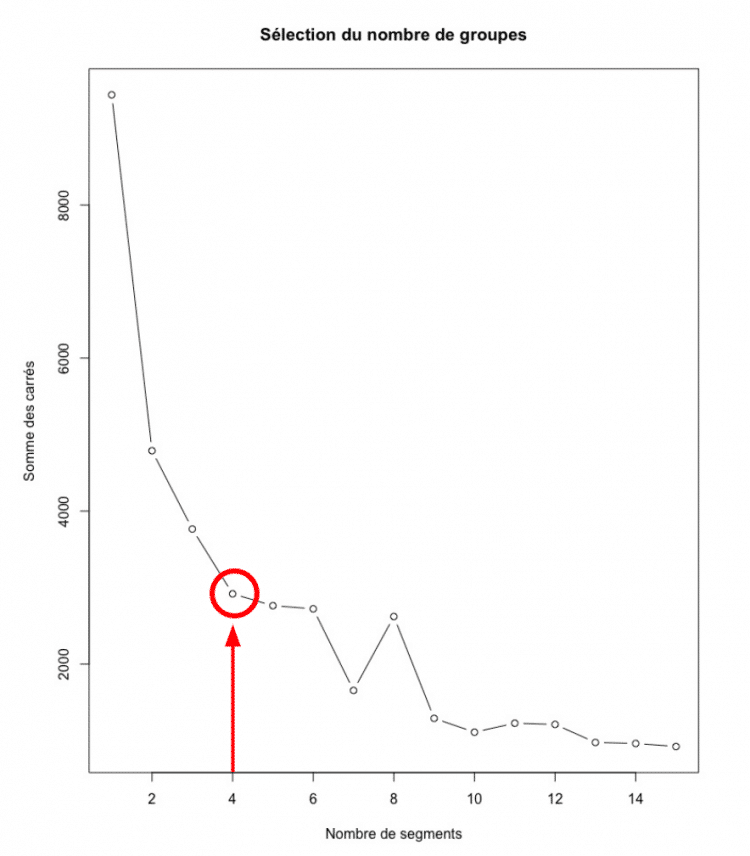
En analysant le tableau, vous constaterez que c’est au bout de quatre segments que la diminution de la somme des carrés commence être de moins en moins importante. Ces quatre segments consistent en un nombre raisonnable pour assurer une facilité d’interprétation. C’est pour cette raison qu’il serait préférable de segmenter votre base de données en quatre groupes. En utilisant une approche bien connue, le k-means, vous pourrez alors procéder à la segmentation de votre base de données. Pour valider si les groupes semblent avoir du sens, vous pourrez également inspecter la visualisation des regroupements.
Code R pour la segmentation K-means
# Segmentation k-means en utilisant la solution des 4 segments identifiés précédemment
kmean_segmentation <- kmeans(segmentation2, 4)
aggregate(segmentation2,by=list(kmean_segmentation$cluster),FUN=mean)
segmentation2 <- data.frame(segmentation2, kmean_segmentation$cluster)
# Visualisation des segments
clusplot(segmentation2, kmean_segmentation$cluster, color=TRUE, lines=0)
Visualisation de notre segmentation
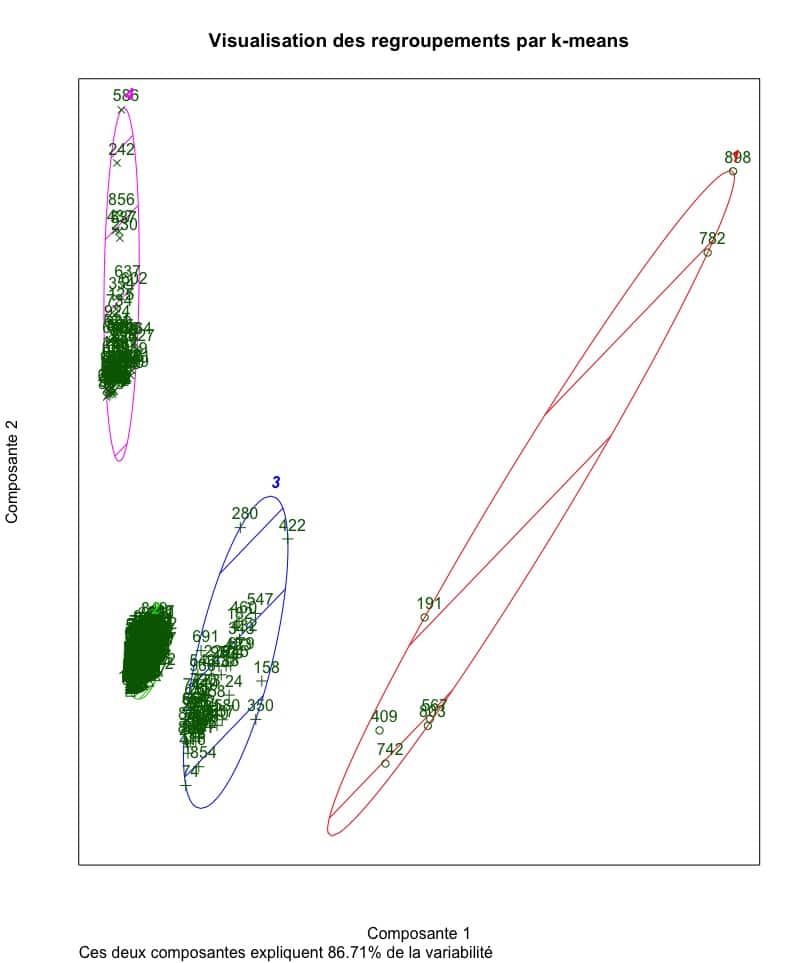
La visualisation des segments créée en utilisant les données de navigation semble conclure que les quatre groupes sont plutôt homogènes. En fait, cet exemple capte plus de 86% de la variabilité qui existait entre les points avant de procéder à l’analyse de regroupement. Voilà donc des informations pertinentes pour dresser le portrait des utilisateurs visitant un site web ou pour mieux comprendre le contexte et les habitudes de navigations.
Ce genre d’approche peut également servir de point de départ dans un processus de création de persona. Les méthodes de recherches mixtes utilisées par Adviso en CX, par exemple, tirent avantage des méthodes de segmentations non supervisées telle que celle démontrée ci-haut.
En vous présentant deux cas d’utilisation concrets de l’utilisation de la donnée que vous possédez probablement déjà, j’espère vous avoir convaincu que l’exploitation des données au-delà des pratiques prescrites est bien plus simple qu’on peut le croire. L’équipe Science de la donnée dont je fais partie se penche constamment sur des problématiques et opportunités de ce genre. Contactez-nous pour discuter de façons créatives d’activer vos données d’entreprise!
Code R utilisé pour la rédaction cet article
#############################################################
#############################################################
# Analyse des données Google Analytics avec R
#############################################################
#############################################################
#############################################################
# Installation des packages requis
install.packages("googleAnalyticsR")
install.packages("tidyverse")
install.packages("reshape2")
install.packages("cluster")
install.packages("fpc")
install.packages("forecast")
#############################################################
# Initialisation des packages requis
library(googleAnalyticsR)
library(tidyverse)
library(reshape2)
library(cluster)
library(fpc)
library(forecast)
# Authentification pour GA. Ouvrez votre fureteur web pour autoriser
ga_auth()
# Sélection des paramètres
view_id <- XXXXXXXX # Insérez ici à la place des X le ID pour VOS données
date_debut <- "2018-01-01"
date_fin <- "2018-12-31"
date_debut_forecast <- "2013-01-01"
date_fin_forecast <- "2018-12-31"
metriques_forecast <- c("ga:sessions")
dimensions_forecast <- c("ga:yearmonth")
metriques_prediction <- c("ga:transactionRevenue", "ga:sessions", "ga:hits", "ga:pageviews","ga:productDetailViews", "ga:timeOnPage", "ga:transactions", "ga:sessionDuration")
dimensions_prediction <- c("ga:dimension10")
metriques_segmentation <- c("ga:sessions", "ga:hits", "ga:pageviews","ga:productDetailViews", "ga:timeOnPage", "ga:transactions", "ga:sessionDuration","ga:bounces", "ga:pageviewsPerSession")
dimensions_segmentation <- c("ga:dimension10")
#############################################################
####### Forecasting des sessions sur un site web ############
#############################################################
# Appel à Google Analytics pour la création du fichier de données
ga_forecast <- google_analytics(view_id, date_range = c(date_debut_forecast, date_fin_forecast),
metrics = metriques_forecast,
dimensions = dimensions_forecast)
# Formatage du data.frame en time series
ga_forecast1 <- dcast(ga_forecast,
yearmonth ~ .,
value.var = "sessions")
rownames(ga_forecast1) <- ga_forecast1$yearmonth
ga_forecast1$yearmonth = NULL
ga_forecast2 <- ts(ga_forecast1, frequency=12)
# Visualisation des sessions sur le site web
plot(ga_forecast2)
# Décomposition de la série en tendance et saisonnalité
forecast_decomp <- decompose(ga_forecast2)
plot(forecast_decomp)
# Forecasting des sessions sur le site web
ga_forecast3 <- msts(ga_forecast2, seasonal.periods = c(12))
forecasting <- tbats(ga_forecast3)
forecasting2 <- (forecast(forecasting))
plot(forecasting2)
#############################################################
############## Segmentation non supervisée ##################
#############################################################
# Appel à Google Analytics
ga_segmentation <- google_analytics(view_id, date_range = c(date_debut, date_fin),
metrics = metriques_segmentation, dimensions = dimensions_segmentation)
# Préparation du fichier de données pour l'analyse de segmentation
segmentation <- na.omit(ga_segmentation)
segmentation2 <- scale(segmentation1)
# Identifier le nombre de segments
within_sum_square <- (nrow(segmentation2)-1)*sum(apply(segmentation2,2,var))
for (i in 2:15) within_sum_square[i] <- sum(kmeans(segmentation2, centers=i)$withinss)
plot(within_sum_square, type = "b")
# Segmentation k-means en utilisant la solution des 4 segments identifiés précédemment
kmean_segmentation <- kmeans(segmentation2, 4)
aggregate(segmentation2,by=list(kmean_segmentation$cluster),FUN=mean)
segmentation2 <- data.frame(segmentation2, kmean_segmentation$cluster)
# Visualisation des segments
clusplot(segmentation2, kmean_segmentation$cluster, color=TRUE, lines=0)