


Un blogue pour mettre les choses en perspective
Bienvenue dans Perspective, un espace de partage de connaissances pour aller au-delà des tendances, développer vos réflexes stratégiques et approfondir vos expertises. Nos experts y partagent des points de vue ancrés dans la réalité et des techniques prêtes à être déployées.

Votre programme de fidélité mesure-t-il les bons KPI?
Après 30 ans en fidélisation, j’ai fait un constat préoccupant: les programmes de fidélité sont souv …

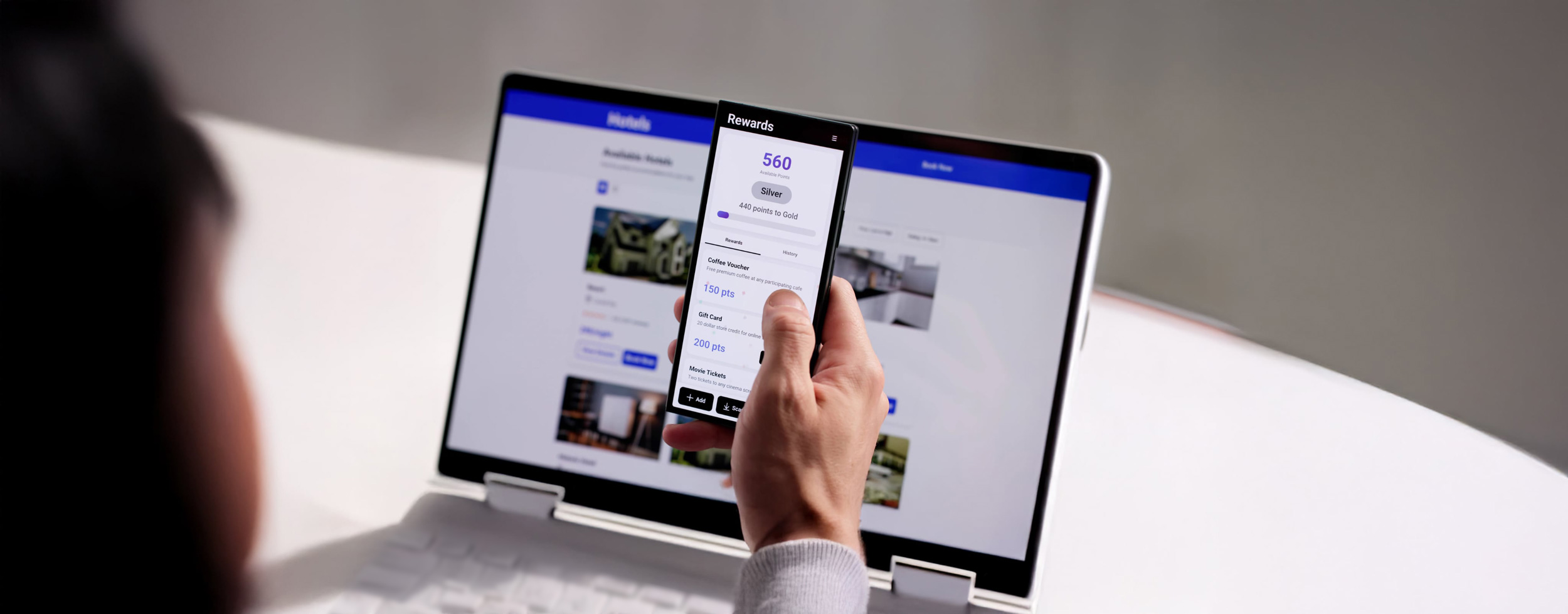
8 erreurs à éviter avec votre application mobile
Votre application mobile est-elle un levier de croissance… ou un silo technologique coûteux?

Les nouvelles règles du commerce de détail à l’ère de l’IA
Nous étions récemment à Toronto pour eTail, une conférence incontournable du commerce de détail en A …

Orchestrateur d'agents IA: vos outils IA ont besoin d’un manager
L’intelligence artificielle bouleverse le marketing.

Programme de fidélité: comment choisir la meilleure plateforme martech?
Le martech en loyauté, c’est une colonne vertébrale invisible. Impossible d’opérationnaliser un prog …
Pourquoi intégrer la gamification dans un programme de fidélisation?
Les Canadien.ne.s participent de plus en plus à des activités de ludification (gamification) au sein …

Top 10 des meilleurs programmes de fidélisation au Canada
La technologie évolue, les attentes des consommateurs aussi. Et, comme eux, la fidélisation se trans …

Meta Andromeda: une révolution IA en paid social?
Meta Andromeda est présenté comme un tournant radical dans la performance publicitaire du groupe Met …

Adobe Customer Journey Analytics, votre prochaine étape
Vous utilisez déjà Google Analytics 4, mais vos questions analytiques deviennent plus complexes et p …
Comment l’intelligence artificielle transforme l’expérience client (CX)
Longtemps, l’intelligence artificielle (IA) a été perçue comme une promesse futuriste. Aujourd’hui, …

Période d'incertitude: comment les marques B2C peuvent (et doivent) s’adapter?
Ces derniers mois, le climat politique a transformé les préoccupations des Canadiens de «Le panier d …

L’IA gouverne Google Ads: et si les marketeurs perdaient la main?
Inspiré de Digital Marketing in an AI World – Frederick Vallaeys

L'ère de l'IA et des réponses instantanées: comment repositionner votre marque pour exister sans clic?
Les comportements de recherche changent vite. Avec l’essor de ChatGPT, Gemini, Copilot et les nouvel …

Les 2 dimensions de la performance des programmes de fidélisation
La plupart des articles et des discussions qui portent sur les programmes de fidélisation traitent e …
Tracking e-commerce Shopify: solutions pour 2025
Depuis avril 2025, Shopify change la donne pour le tracking e-commerce. Les intégrations traditionne …

Salesforce Data Cloud: Valorisez vos données Google Analytics 4 (GA4)
Vous utilisez Salesforce (SF) Data Cloud ou envisagez de l’intégrer à vos technologies marketing (Ma …

Content Security Policy (CSP): votre sécurité web bloque-t-elle vos données?
Les politiques de sécurité des contenus (Content Security Policy ou CSP) sont aujourd'hui considérée …

La chute de La Baie: quelles leçons pour les détaillants?
L'annonce de la fermeture des magasins La Baie d'Hudson marque la fin d'une époque pour l'une des en …

Les agents d'intelligence artificielle (IA): l'avenir de la productivité
L’intérêt élevé porté à l’intelligence artificielle (IA) générative, spécifiquement aux agents IA et …

Stratégie média durable: allier performance et environnement
Très énergivores, les médias ont un rôle clé à jouer dans la lutte contre la crise climatique. Bonne …

Intelligence artificielle (IA): pistes de solutions pour une utilisation plus éthique et écologique
L’intelligence artificielle (IA) est devenue une composante essentielle de nombreuses activités huma …

Top 10 des meilleurs programmes de fidélisation au Canada en 2024
Adviso et R3 Marketing, en collaboration avec Ad hoc recherche, ont dévoilé à l’automne 2024 la 7e é …

Search GPT va-t-il remplacer Google ? Ce que vous devez faire pour rester à la page
La réponse courte : Search GPT ne remplacera pas Google dans l’immédiat, mais il redéfinit la recher …

L’avenir de la programmatique : comment les DSP et l’AdTech transforment la publicité numérique
La publicité programmatique est devenue un levier clé dans la transformation des interactions entre …
Repérer et valoriser ce qui compte vraiment.
Recevez nos analyses et conseils pour rester à l’avant-garde du marketing.